



分享资料个
本文转载自:网络交换FPGA微信公众号
推荐一篇论文,论文题目翻译过来为:自适应交换机:用于网络中心计算的异构交换机体系结构。该论文可以认为是一篇介绍DPU架构的文章。文章由新加坡Xilinx/西交大的 胡成臣老师共同撰写,发表在2020年12月IEEE Communication Magazine上,其主旨思想,是利用FPGA作为协处理器,补充现有可编程交换ASIC的不足,给出了三个场景(NDP、DISCO、Stateful Firewall)作为例证;代码已在Github开源。一个新兴的范例是采用SmartNIC进行以网络为中心的计算,它在主机的网络接口上引入了特定于用户的处理。作者采取了这一举措,进一步解决了网络核心(交换机)中当前专有的处理和计算问题。链接:https://ieeexplore.ieee.org/abstract/document/9311937.
以网络为中心的计算可将计算和数据处理从CPU卸载到并分解到CPU,以支持不断增长的吞吐量,大数据量和数据中心的信息复杂性。一个新兴的范例是采用SmartNIC进行以网络为中心的计算,它在主机的网络接口上引入了特定于用户的处理。在本文中,我们将进一步采取主动行动,以解决网络核心(交换机)中当前的专有处理和计算问题。我们提出了一种新的硬件架构,称为自适应交换机。基于对其支持三个用例的原型的测试,我们证明了在可适应的交换机上可以同时实现高吞吐量和处理灵活性。

1. 引言
在严格的延迟要求下传输海量数据的需求不断增长,并将CPU推向了现代数据中心可扩展性的极限。从数据中心到网络接口卡(NIC)的卸载网络堆栈和计算已越来越多地部署在数据中心中[1]。这种方法称为SmartNIC,它使人们进一步拥抱网络内计算或以网络为中心的计算,以通过网络卸载和分解计算,存储和其他功能。在本文中,我们提出了一种适应性强的交换机体系结构,以支持网络核心中的用户特定处理和专有协议,以补充主机网络中现有的SmartNIC。
引入用户定义的流量穿越交换机的动作的开创性工作是OpenFlow交换机[2]。这个相当不灵活的数据平面后来被开发成为便携式交换机架构(PSA)[3]。可以从独立于编程协议的分组处理器(P4)语言[4]灵活定义和编译PSA兼容数据平面目标。PSA存在一些局限性,这些局限性促使了本文的工作。
首先,PSA仅在数据包到达和/或离开时触发处理,从而不支持其他事件的操作。例如,在PSA中,很难在新颖的数据平面传输协议(NDP)[5]提议中启用控制,在这种提议中,当缓冲区拥塞时,交换机应该做出反应。稍后将在我们的实验中详细介绍NDP的一个使用案例。
其次,PSA在计算操作(例如,代数计算)方面缺乏能力,这阻止了在PSA兼容交换机上部署许多算法。稍后将讨论一个利用复杂计算的流量统计方法(折扣计数,DISCO [6])的具体示例。
第三,PSA最初是为对网络数据包进行无状态处理而设计的。PSA通常很难基于历史状态进行状态协议处理和/或状态计算。为了更好地理解这一点,稍后将讨论防火墙[7]用例。
PSA非常适合无状态和基于转发的数据平面,但是我们的目标远不止PSA的范围:我们的目标是设计一种交换架构,以将计算量卸载和分解到网络中。在语言级别,P4的最新版本(P4_16)引入了P4_extern的概念,以描述该语言的标准格式不支持的任何功能。但是,没有灵活的交换机体系结构具有匹配的“ PSA_extern”用于由P4_extern定义的处理。解决方案始终是在添加新的P4_extern时具有新的专用硬件目标。但是,这与PSA作为便携式可编程数据平面的最初思想相冲突,应该避免。
我们通过提出一种异构硬件交换机体系结构来进行创新,以支持任何可能的P4_extern定义的处理。我们将此架构命名为自适应交换机,我们已经解决了两个技术挑战,这是我们的主要贡献。第一个是自适应交换机的异构硬件体系结构设计。第二个是如何基于自适应开关以最佳方式开发程序并将其映射到目标。据我们所知,这是第一个开关架构,既提供现场可编程门阵列(FPGA)级别的可编程性,又达到与切换专用集成电路(ASIC)相当的吞吐量。借助提出的自适应交换机体系结构,我们可以消除对P4兼容ASIC芯片的限制,并支持事件触发,复杂的算术计算和状态处理,所有这些都以线路速率实现。为了评估我们的建议,我们在一个可适配交换机的原型上实现了三个用例,并在评估部分与其他可编程数据平面进行了比较。
2. 架构设计
图1是自适应交换机的硬件架构的框图。它由固定交换系统(SS)部分和用户可编程逻辑(PL)部分组成。SS部分实现了标准交换功能,而PL部分则部署了FPGA以对定制处理进行编程。所提出的体系结构中的SS和PL这两个部分可以通过两芯片方法来实现,其中SS可以是具有或不具有P4兼容性的传统交换ASIC,PL可以是FPGA芯片,即片上多处理器系统(MPSoC)或将FPGA与其他处理器(例如ARM内核)集成在单个SoC中的自适应计算加速平台(ACAP)芯片。在两芯片解决方案中,两个物理上分离的芯片使用PCle或以太网接口或收发器连接。或者,我们还可以用一个高带宽片上总线(如AXI)来实现单芯片的解决方案。
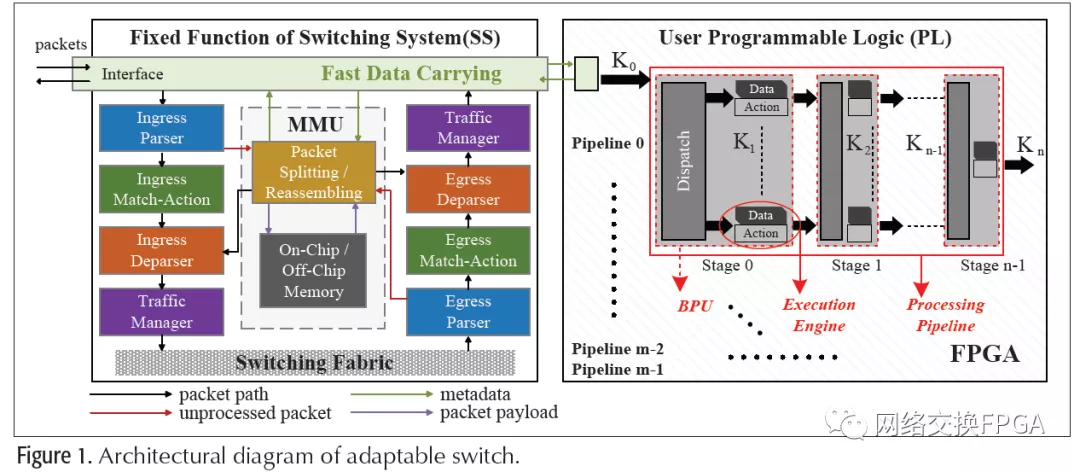
SS中的交换结构通常采用交叉开关在入口和出口之间进行高速交换。来自网络接口的数据包在交换矩阵之前/之后经过入口/出口管道。在入口或出口管道中,通常有解析器(提取感兴趣的标头字段),流表(与提取的标头匹配以执行操作),解析器(重组或/和操作数据包)和流量管理器(缓冲区管理,数据包调度,整形等)。
所有传入的数据包都首先进入SS,并且大多数数据包完全在SS中处理。只有那些依赖于SS不支持的功能的分组才会被进一步发送给PL进行协同处理。在数据包触发PL中的处理的情况下,SS将数据包存储在片上或片外存储器中,并将专用元数据发送到PL。自定义元数据以承载从PL中进行处理所需的数据包中提取的信息。PL中的处理将更新元数据并将其返回给SS。SS将原始数据包与返回的元数据合并为一个完整的数据包以进行转发,或者只是丢弃该数据包。
我们引入了一个额外的内存管理单元(MMU),如图1所示。MMU管理内存以缓冲等待PL更新元数据的数据包。更具体地说,它包括三个主要功能:
1、动态分配存储块以存储数据包。
2、将数据包数据写入内存。
3、从内存中读回存储的数据包数据,并使用从PL返回的元数据组装输出数据包。
我们基于两个观察或假设来设计自适应交换机体系结构。
1、PL中的大多数处理通常仅基于数据包头或/和有效载荷中前几个字节的数据包段。我们的设计仅交换可以灵活定义的元数据,从而保证了SS和PL之间有限的互连带宽消耗。在极少数情况下,查看整个数据包的处理将用整个数据包填充元数据。
2、并非所有流量都需要在PL中进行处理:否则,相关功能将成为现成交换ASIC的一部分,或者直接转移到自适应交换体系结构中的SS部分。
考虑到平均数据包长度约为600B,并且假设元数据大小为64B,如果通过PCle Gen4*16进行接口连接,则在不牺牲端口密度的情况下,即使使用最大的交换,也可以在PL中进一步处理20%的流量以12Tb/s作为SS的ASIC。在两芯片解决方案中,允许10%的端口密度连接SS和PL,同样,在平均数据包长度为600B,元数据为64B的情况下,所有原始流量可以在PL中进行进一步的处理。
3. PL中用户定制处理流程
为了有效地映射PL中基于用户特定数据流的计算,我们引入了微并行处理流水线,如图1右侧。我们将每个处理阶段抽象为一个基本处理单元(BPU)。通过将输入流量负载分配给多个执行引擎,还为每个BPU引入了并行性。执行引擎由操作模块组成,该模块对保存在内存中的一组数据进行操作。在通用BPU抽象中,到BPU的输入(数据流)数量与其前身的执行引擎数量相同,但对于一个BPU中的输入和输出数量而言,不一定相同。
数据拆分的优化问题是NP难题,可以从多项式时间的平均除法问题中减少。遵循模拟退火算法解决平均分割问题的思想,我们开发了一种启发式算法,用于将与流程相关的处理相关数据映射到每个执行引擎中。
在本节的其余部分,我们将回答有关此PL体系结构的两个问题:
1、如何为BPU开发操作模块以适合特定于用户的PL。
2、如何在每个BPU中正确地填充数据内存,以便调度模块可以尽可能均匀地分配流量负载,从而最终最大化处理吞吐量。
开发流程
我们使用Xilinx P4-SDNet[8]作为开发流程的基础来构建我们的原型,如图2所示。P4-SDNet是一种现成的商用产品(COTS),涵盖了从P4语言到SDNet规范,再到基于FPGA的数据平面的编译工具链。P4-SDNet产品的最新版本支持P4_16,提供了两个内置的P4_externs。内置的P4_externs支持通过使编译器前端能够识别高级描述来展示将编译器扩展到更多用户特定处理的方法。另外,我们在编译器后端使用注释,这些注释将转换为适当的中间表示(IR)(例如SDNet [9])。规范),最后映射到PL。一般而言,对于用户特定的PL,还可以使用硬件描述语言(Verilog HDL,VHDL等)进行编码,然后编译为BPU和PL中的处理管道,这是另一种选择。

优化
如前所述,BPU中的调度模块将流量负载分配给BPU中的多个执行引擎。稻草人解决方案将所有与处理相关的数据复制到每个执行引擎,这通过以循环方式分配流量负载来简单地实现大吞吐量。但是,每个执行引擎中数据存储器的大小是有限的,不足以容纳处理相关数据的完整副本。由于这个原因,通过回答在每个执行引擎中保留完整处理相关数据的哪个子集来解决数据拆分和分配问题并非易事。目的是通过平衡每个执行引擎中处理的工作量来最大化并行处理吞吐量。不失一般性,我们使用流表来保持对相关数据的处理,并将其表示为一种优化问题。
对象
最大程度地增加可发送到每个执行引擎的工作量。
约束
约束处理
单个执行引擎具有最大吞吐量,无法将更多的负载分派到达到容量限制的执行引擎。
流关联约束
来自同一流的所有数据包应该由同一处理流水线的同一执行引擎处理,以保持处理依赖关系,避免出现无序问题。
调度约束
流的处理只能调度到执行引擎(其中一个),在该执行引擎中分配要处理该流的数据(例如,执行引擎中的流表具有该流的信息条目)。
内存大小约束
如果数据存储器的大小小于完整处理相关数据,则只能将完整数据的一部分(例如流表)放入执行引擎中。引入更多的数据副本可以减轻数据访问冲突,但需要更多的(片上)内存,因此流可能在执行引擎之间具有冗余性。
数据分割的优化问题是NP难问题,可以从多项式时间内的平均分割问题中得到简化[10]。根据模拟退火算法求解平均分割问题的思想,我们开发了一种启发式算法,用于将与处理相关的流数据映射到每个执行引擎中。我们介绍了该算法的主要思想;有关详细信息,请参阅github网站[10]上的代码。首先,我们使用散列函数将流拆分为多个组;每个组的处理相关数据少于执行引擎可以承载的数据(数据大小约束)。请注意,如果流的汇总工作负载需要多个执行引擎(处理约束),则有包含相同组的执行引擎。其次,我们首先将流组映射到不同的执行引擎中,而不破坏约束。第三,以迭代的方式,我们通过将一个流组从一个源执行引擎随机移动到另一个目标引擎来调整流组分配到执行引擎。执行引擎的工作负载越多,它将流组移出的概率就越大;而选择移动组的目标执行引擎的概率与执行引擎的工作负载成反比。如果通过约束检查的调整能够改进对目标的评估,那么它将以很大的概率被接受(为了跳出局部搜索陷阱,并不总是接受)。在找到足够好的解决方案或达到预设的迭代轮数后,调整迭代停止。
在实际应用中,作为启发式算法输入的流量分布随着时间的推移而变化,因此使用远程控制器来收集执行引擎之间的工作负载变化,作为运行时重新计算和配置的反馈。算法的计算时间评估如下。
3. 评测
我们已经在Xilinx ZC706开发板上实现了自适应开关的原型,其中包含4000余行代码,包括SS函数,PL映射优化算法和PL中的三个用例。可以在github [10]上访问测试代码,在开发过程中我们引用了NetFPGA使用的P4-SDNet工具集的代码库。我们利用五种跟踪进行评估,包括从ISP主干收集的一条真实ISP跟踪,从LTE基站收集的一条LTE跟踪,以及按照跟踪名称指示的分布的三种综合跟踪(指数跟踪,帕累托跟踪和统一跟踪)。
使用案例
拥塞控制:NDP [5]确保在交换机中检测到拥塞时小批量数据包的低转发延迟。NDP是事件驱动处理的一个示例,现有交换机无法很好地支持它。为了在自适应交换机中部署NDP,我们在SS部分的MMU中分配逻辑输出队列。PL中实现了两种NDP操作:一种监视队列深度作为拥塞触发信号,另一种发送显式通知以调整数据包大小。前端编译器将用户逻辑包装到操作模块中,以生成BPU和处理管道。
网络测量:DISCO [6]是一种有效的流量统计算法,但是由于缺乏指数和对数计算支持,因此在(P4或非P4)COTS交换机中部署DISCO颇具挑战性。在我们的自适应交换机上的DISCO实现中,PL的输入元数据包括流ID和每个传入数据包的长度,而输出是保存在片上存储器中的流统计计数器值。我们使用Verilog HDL为DISCO实现P4_extern函数。
有状态防火墙:我们还提供了一个有状态防火墙[11]转发引擎,其形式为可适配交换机支持的P4_extern功能,这对商品交换机是一个挑战。实现的引擎记录用于过滤数据包的连接状态。实现了两个硬件流表:一个用于基本匹配操作,另一个存储每个相应流的状态列表。当来自流的数据包到达时,它根据当前流状态和感兴趣的数据包字段执行操作。它还更新匹配操作表以指示下一个状态。
4. 实验结果
我们量化了原型的五种硬件资源消耗。查找表(LUT)用作组合逻辑实现。LUT随机存取存储器(LUT RAM)是用于缓存短变量值的寄存器资源。触发器(FF)电路单元可以由时钟信号驱动,以建立时序逻辑。Block RAM(BRAM)是片上大型存储单元。数字信号处理器(DSP)是分布式快速单时钟周期数学计算核心。
在表1中,我们展示了当我们为每个用例启用一个分派和20个执行引擎时的结果。表中的结果以“数量/比例”的形式显示,其中我们显示了实现原型的FPGA的确切消耗量和占总资源的比例。dispatch行同时考虑了20个解析器(SDNet生成)和一个2020交换机(具有20个均衡器体系结构)的消耗,以将流量负载分配给执行引擎。对于这三个case行,每个执行引擎都包含一个精确匹配表(200个条目)作为数据存储(在实践中可以根据需求和硬件容量进行调整)。在拥塞控制用例中,对于拥塞控制用例,有20个输出端口的40个优先级队列,每个端口的队列大小为64 kB。此外,我们还部署了20个计数引擎,在测量情况下总共有4k计数器,在防火墙情况下有20个可编程状态转换表。随着使用的执行引擎、阶段、管道和条目数量的增加,资源消耗几乎呈线性增加。从结果中,我们观察到一个典型的FPGA足以部署这三个用户案例。

图3中,我们描述了增加执行引擎数量时的吞吐量趋势。我们根据最大频率、数据总线宽度和平均数据包大小(600b)计算吞吐量。使用更多的执行引擎时,最大频率会下降,而使用20个以上的执行引擎时,吞吐量增益会变得平缓。我们观察到,对于拥塞控制和测量用例,原型最多达到8tb/s左右,对于有状态防火墙用例,原型最多达到6tb/s左右的吞吐量。
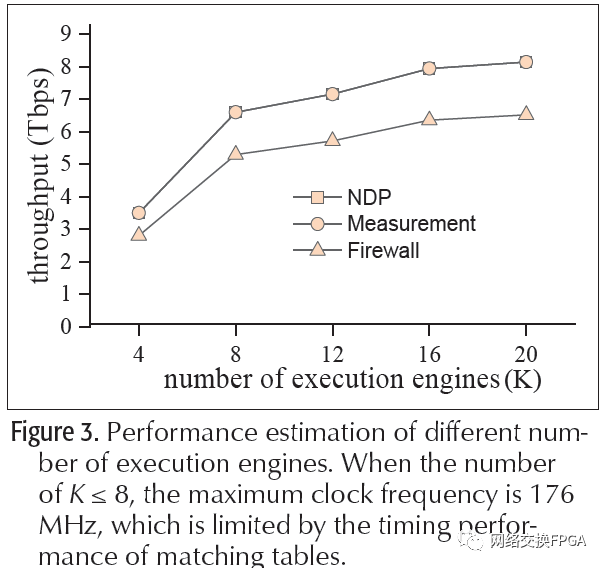
通过查看每个用例所需的周期,我们将拥塞控制、网络测量和防火墙用例的PL处理延迟分别确定为0.130ms、0.136ms和0.142ms。
我们还使用300多行Python代码在运行时进行配置来实现PL映射优化,并使用PyPy工具集将其部署在Dell R620服务器(具有8G RAM和运行Ubuntu 16.04 LTS OS的2.80 GHz四核Intel CPU)中。和即时(JIT)编译器来加速Python程序。图4绘制了本节前面介绍的五个流量跟踪下的平均计算时间。共有五个烛台组,分别代表执行引擎(具有一个阶段和一个处理管道)数量的不同设置,即K = 4、8、12、16和20个执行引擎。K值较大时,运行时映射优化需要花费较长时间。使用20个执行引擎,在我们测试的所有跟踪下,计算时间不到8.30 s,置信度为95%。
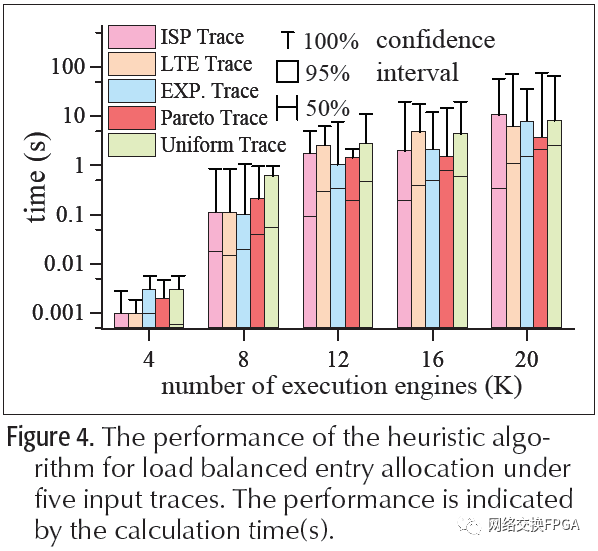
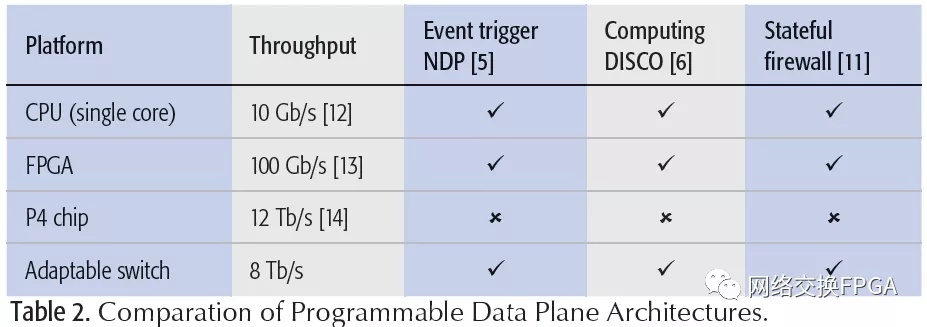
表2总结了各种常见可编程数据平面的特征,例如,基于软件的交换机[12]、基于FPGA的交换机[13]和基于P4兼容交换ASIC的交换机[14]。在介绍[11]中,我们提到了很多基于事件驱动的ASIC和基于触发的ASIC的特性,而在介绍[11]中,我们提到了基于事件驱动的ASIC和基于触发的ASIC的特性。所提出的可适应性交换机将其自身定位在设计空间中,具有与基于纯软件/FPGA的交换机相似的可编程性和与P4兼容ASIC相当的(稍微低一点)吞吐量。
5. 结论
我们提出了一种适用于网络中心计算的自适应交换体系结构。Adaptive switch背后的关键是利用交换系统提供高吞吐量,同时将硬件可编程处理卸载到FPGA上。我们已经实现了一个原型和三个用例。实验表明,该结构的灵活性优于现有的固定功能交换机。此外,所实现的设计可以很好地控制资源消耗,以每秒数太比特的速率提供处理吞吐量。尽管PL部分的处理吞吐量仍然小于交换ASIC的吞吐量,但是我们认为,整个分组或所有数据流都不需要在PL中使用用户定义的处理来处理,因此,自适应交换体系结构具有与COTS交换机兼容的总吞吐量。
参考文献
[1] G. Lu et al., “Serverswitch: A Programmable and High Performance Platform for Data Center Networks,” Proc. 2011 USENICS NSDI, Boston,MA, vol. 11, 2011.
[2] N. McKeown et al., “OpenFlow: Enabling Innovation in Campus Networks,” ACM SIGCOMM CCR, vol. 38, no. 2, 2008,pp. 69–74.
[3] P4.org Architecture WG, “Portable Switch Architecture (PSA),” Nov. 2018; https://p4.org/p4-spec/docs/PSA-v1.1.0.html, accessed July 15, 2020.
[4] P. Bosshart et al., “P4: Programming Protocol-Independent Packet Processors,” ACM SIGCOMM CCR, vol. 44, no. 3, 2014, pp. 87–95.
[5] M. Handley et al., “Re-Architecting Datacenter Networks and Stacks for Low Latency and High Performance,” Proc. 2017 ACM SIGCOMM, Los Angeles, CA, 2017, pp. 29–42.
[6] C. Hu et al., “Disco: Memory Efficient and Accurate Flow Statistics for Network Measurement,” Proc. 2010 IEEE ICDCS, Genova, Italy, 2010, pp. 665–74.
[7] S. Zerkane et al., “Software Defined Networking Reactive Stateful Firewall,” Proc. 2016 IFIPSEC, Ghent, Belgium, 2011, pp. 119–32.
[8] Xilinx, “User Guide: P4-SDNet Translator,” Jan. 2017; https://www.xilinx.com/support/documentation/sw_manuals/xilinx2017_1/ug1..., accessed July 15, 2020.
[9] Xilinx, “User Guide: SDNet Packet Processor,” Jan. 2017; https://www.xilinx.com/support/documentation/sw_manuals/xilinx2017_1/UG1..., accessed July 15, 2020.
[10] S. Qiao et al., “Testing Code of Adaptable Switch Project,” Sept. 2020; https://github.com/Adaptable-Switch/AS_test/, accessed Sept. 21, 2020.
[11] S. Pontarelli et al., “Flowblaze: Stateful Packet Processing in Hardware,” Proc. 2019 USENICS NSDI, Boston, MA, 2019, pp. 531–48.
[12] M. Shahbaz et al., “Pisces: A Programmable, Protocol-Independent Software Switch,” Proc. 2016 ACM SIGCOMM, Florianopolis, Brazil, 2016, pp. 525–38.
[13] H. Wang et al., “P4FPGA: A Rapid Prototyping Framework for p4,” Proc. 2017 ACM SOSR, Santa Clara, CA, 2017, pp.122–35.
[14] P. Bosshart et al., “Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN,” ACM SIGCOMM CCR, vol. 43, no. 4, 2013, pp. 99–110.
[15] S. Ibanez et al., “Event-Driven Packet Processing,” Proc. 2019 ACM HOT NETS, Princeton, NJ, 2019, pp. 133–40.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉



全部0条评论

快来发表一下你的评论吧 !
