

今日头条
随着深度学习、CAE仿真、大数据分析、动画渲染、图像分析、高性能计算的快速发展和个性化服务的不断演进,大型互联网公司在服务用户过程中积累了海量数据。此外,数据的频繁跨境、跨系统、跨生态圈交互已成为常态,加剧了隐私信息在不同信息系统中有意、无意留存,但随之而来的隐私信息保护短板效应、隐私侵犯追踪溯源难等问题越来越严重,致使现有的隐私保护方案不能提供体系化的保护。
12月21日,由中国信息通信研究院和中国通信标准化协会联合主办的“2021可信隐私计算高峰论坛暨数据安全产业峰会”在北京举行。
会上各个专家从数据安全、构筑安全可信的数据互联互通的基础设施、围绕隐私计算的底层关键技术、深入解析隐私计算的算力及通信挑战提出了见解与看法。
数据安全
专家深入分析了政务数据流通、金融数据流通、保险数据流通面临的问题,提出了数据安全的新观点。将数据安全分为四层:
第一层:数据传统安全,包括数据的保密性、完整性和可用性。
第二层:数据作为生产要素在流通过程中的权益和安全。
第三层:互联网平台企业收集海量数据形成的数据霸权。
第四层:可能影响国家安全的数据主权。
这四层互联互通。例如,个人隐私保护本质上是属于数据保密性的范畴,但在大数据环境下,也与第二层和第四层相关。
专家表示:只有安全地使用数据,数据作为生产要素的价值才能得到释放。在数据安全流通领域,为公共数据和社会数据按需安全开放创造更多应用场景,推动数字化转型,激发数字经济活力将成为一大课题。
构筑安全可信的隐私数据
互联互通基础设施
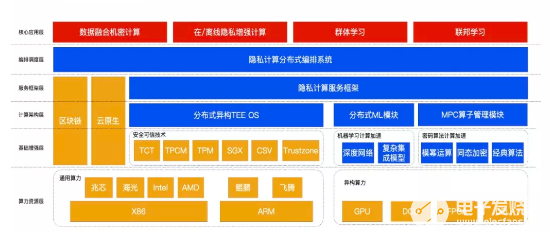
隐私计算技术发展到现阶段面临着一个临界点,即隐私计算能否从一项创新型技术走向大规模生产和应用。在这个过程中,隐私计算的技术服务商面临两大挑战:
一:如何在实际业务中更广泛地应用隐私计算?
隐私计算作为保障数据隐私安全的技术,必然会入侵和影响现有的数据业务系统。对于试图引入隐私计算的客户来说,隐私计算技术服务商能否打消他们对业务受损的担忧,是客户能够深度拥抱隐私计算的前提。因此,降低隐私计算带来的性能损失,提高隐私计算平台的通用性和可扩展性,为现有数据服务中的上下游系统提供充分的兼容性,是隐私计算技术服务商需要考虑的关键问题。
二: 如何充分信任隐私计算的安全性?
虽然从技术角度来看,隐私计算的每一条技术路线都有其自证的逻辑,但对于最终客户来说,对这项技术信任的建立不能仅仅依靠技术论证本身。做好技术标准化,实现技术栈自主可控国产化,建立权威和监管机构认可的标准体系,也是隐私计算厂商需要推动和解决的问题。
面对上述一系列挑战隐私计算技术发展的六大突破总结如下:
1.多技术路线有机融合:
通过实现跨技术路线的互联互通,降低不同技术路线客户的选型成本。
2.国产化生态深化:
隐私计算上下游与数据库、数据治理等国产软件服务商形成深度合作。
3.软硬件深度优化突破:
性能层面,通过软硬件深度优化实现计算效能的突破。
4.隐私计算的可信增强:
通过技术和非技术手段具有更强的可信度。
5.离线计算全面覆盖:
在隐私计算目前覆盖的建模训练、统计分析等线下场景之外,针对数据处理等线上场景,扩大隐私计算技术的覆盖范围。
6.工业级别工程化落地:
稳定性和可用性方面,面对数亿样本甚至更大的数据量级,隐私计算平台的生产可用性仍有保障。
高性能算力加速构建数据
安全流通网络
人工智能的发展与大数据息息相关。AI 的成功基于大量的数据。但在行业内,由于数据安全相关法律法规的相继颁布实施,对数据的管理和使用日趋严格。医疗、政务、金融等高质量、规模化的数据通常以数据孤岛的形式分散在不同的机构和行业,难以聚集起来进行人工智能建模。
在严监管的情况下,解决数据供给和数据安全防护的双重需求逐渐成为各行业普遍存在的问题。因此,“数据可用不可见、数据不动模型动”的特性使其迅速“出圈”,备受业界关注。就像一条小溪流入江河大海。借助深度学习技术,把分属于不同机构的数据汇集在一起,分离数据所有权和使用权,将小数据聚合成大数据,以安全合规的方式进行建模培训,是企业数字化转型的重要支撑。
从技术层面来看,在原始数据不出域的前提下,实现了数据价值的高效转移,既满足了监管对数据安全保护的要求,又使得数据生产要素功能的高效转移成为可能,同时释放了人工智能和机器学习工业应用的增量需求。
作为人工智能和大数据的重要关键技术延伸,深度学习技术大规模应用于政务、金融、医疗等领域渐成重要趋势。然而,由于深度学习中大量密码算法的引入,效率是大规模深度学习系统的关键挑战。
不解决算力和通信问题,隐私计算的大规模应用将无从谈起。面对隐私计算的算力和通信压力,通过对隐私计算的大量实验和分析,深度学习的计算能力挑战主要来自两个方面:
计算压力
深度学习使用大量的密文计算,加密后的数据计算会产生大量的计算能力开销,单模型训练和迭代的耗时会呈指数级增长。即使使用最小位数进行加密计算,如1024bit密钥位宽,相较于明文计算慢数十倍。随着秘钥位宽的增加,隐私计算的实际运算效率会出现指数级的差异。
通信压力
与传统的分布式学习技术相比,现在的学习模型分布在不同机构和行业的参与方。因此,深度学习的实际应用往往需要频繁的通信来交换中间结果,并且使用秘密状态来传输中间结果,进一步降低了数据传输的效率。
蓝海大脑深度学习平台广泛应用于各个领域,液冷GPU工作站搭建于 NVIDIA 4 × A100 / 3090 / P6000 / RTX6000;使用 NVLink + NVSwitch的最高GPU通信;4个用于 GPU Direct RDMA的NIC(1:1 GPU比率);最高4 x NVMe用于GPU系统盘,带有 AIOM。为隐私计算的发展保驾护航。
审核编辑:符乾江
全部0条评论

快来发表一下你的评论吧 !

