

如果您曾经使用过虚拟助手,您可能会认为您正在与一台非常智能的设备交谈,它几乎可以回答您提出的任何问题。嗯,实际上,Amazon Echos、Google Homes 和其他类似的设备通常不知道你在说什么。
是的,这些设备利用了人工智能。但不是你期望的那样。端点硬件通常会简单地检测到唤醒词或触发短语并打开与自然语言处理引擎分析请求的云的连接。在许多情况下,他们不只是传输您的问题的记录。
“我们将其称为边缘的‘弱唤醒词’,”加利福尼亚州帕洛阿尔托的 Knowles Intelligent Audio 物联网营销高级总监 Vikram Shrivastava 说。“你仍然需要将整个录音发送到云端,以获得真正可靠的第二秒,即有人真正说‘好吧,谷歌’或有人真正说出了相关的触发词。
“这将产生我们称之为检测和错误接受的真阳性率 (TPR),”他继续说道。“所以,如果你没有说 Alexa,但它还是向云端发送了一条消息,那么云端就会说,‘不,你没有。我仔细检查过,你错了。那是因为边缘设备的边缘检测算法不够复杂。”
换句话说,许多虚拟助手至少会访问云端两次:一次是为了验证他们是否被寻址,第二次是为了响应请求。
没那么聪明吧?
边缘对话
这种架构有几个缺点。将请求发送到云会增加时间和成本,还会使潜在的敏感数据面临安全和隐私威胁。但这种方法的最大限制因素是打开和维护这些网络连接会消耗能量,这会阻止语音 AI 部署在所有电池供电的产品中。
挑战就在这里。许多边缘设备使用的节能技术不具备在本地运行 AI 的性能,因此必须将语音命令发送到云端,这会招致前面提到的惩罚。为了摆脱这个循环,Knowles 和其他地方的音频工程师正在将数字信号处理器 (DSP) 的传统效率与新兴的神经网络算法相结合,以提高边缘智能。
“我们现在看到的是边缘设备开始向内置生态系统过渡,”Shrivastava 解释说。“所以现在你可以拥有多达 10、20、30 条命令,这些命令都可以在边缘本身执行。
“一些触发词改进显着改善了边缘的 TPR,”他继续说道。“音频 DSP 实际上发挥了重要作用,而边缘的音频算法发挥了重要作用,这只是在嘈杂环境中检测这些触发词的性能。因此,如果我的真空吸尘器正在运行并且我正在尝试发出命令,或者您在厨房并且排气扇正在运行并且您正在尝试与您的 Alexa 设备交谈。
“这就是我们所说的低信噪比,这意味着你所处的环境中的噪音非常高,平均谈话会低于平均噪音。”
Knowles 是一家无晶圆半导体公司,以其高端麦克风和最近的音频处理解决方案而闻名。后者始于 2015 年 Knowles 收购 Audience Inc.,该公司成立于计算听觉场景分析 (CASA) 的学术研究,研究人类如何对与其他频率混合的声音进行分组和区分。这项研究导致专门的音频处理器能够以 Shrivastava 描述的方式从背景噪声中提取一个清晰的语音信号。
除了这些音频处理器之外,Knowles AISonic 音频边缘处理器等产品还集成了来自 Cadence Design Systems 的 DSP IP 内核。Cadence 的 Tensilica HiFi 音频 DSP 产品组合因其高能效和高效数字前端和神经网络处理能力而在智能边缘语音应用中广受欢迎。
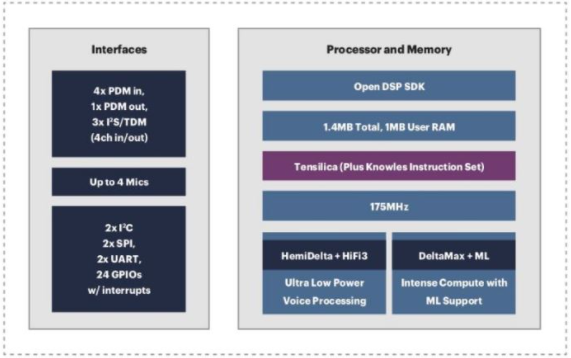
图 1. Knowles 将 Cadence Tensilica HiFi DSP 内核集成到其 AISonic 音频边缘处理器中。
Knowles 将这些基于 Tensilica 的音频处理解决方案部署到从单麦克风 AISonic SmartMics 到高端设备(如高端 Honeywell 或 Nest 级恒温器)的所有设备中,它们可以管理三到七个麦克风。
“麦克风是数字的,DSP 是数字的,DSP 和主处理器之间的通信也是数字的,”Shrivastava 说。“我们就说它是一个 Ecobee 设备。那里有一个基于 Arm 的主机处理器,它运行一个小的 Alexa 堆栈,它将接受来自 Knowles 子系统的命令短语。
“我们可以接收核心麦克风数据,我们可以进行波束成形,我们可以找出你在哪个方向说话,我们可以只改善和放大来自那个方向的信号,忽略来自另一个方向的噪声,做一些其他噪声抑制也是如此,然后准确地检测到触发词,”他继续说道。“在一个经过良好调整的系统中,我们在 24 小时内会出现少于三个错误检测。我们可以在 1 MB 的内存中完成这一切。
“拥有所有这些背后的价值主张,只是为了给你一个想法,如果你需要一个运行在 1 GHz 的 Arm 内核来进行语音处理,我们将在我们的 DSP 上以大约 50 MHz 运行相同的进程,所以几乎是 20 倍,”Knowles 工程师解释道。“这直接转化为功耗。”
显然,Tensilica 核心无法提供 Shrivastava 所描述的开箱即用的效率水平。应用工程师必须针对最终用例调整系统。对于 Cadence Tensilica 客户,此过程因定制说明的可用性而得到简化。
“Tensilica 的独特之处之一是能够使用 Tensilica 指令扩展或 TIE,”Cadence 产品营销总监、Knowles 前员工 Adam Abed 说。“Knowles 广泛使用它来定制和构建非常高效的浮点处理。
“因此,我们共同打造了这款非常出色、独特的产品,它不仅能够从 MEMS 和麦克风的角度提供高质量的音频,而且还可以在不醒来的情况下以超低功耗的方式进行清理或语音触发等操作系统的大部分内容,”他补充道(图 2)。
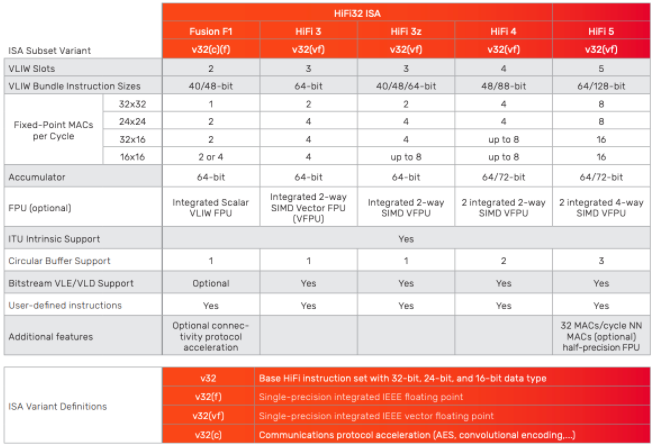
图 2. Cadence 的 Tensilica HiFi 系列 DSP 提供性能可扩展性和指令定制,以满足一系列智能语音处理系统的要求。
为了最大限度地提高电源效率和 AI 性能,Abed 提到的唤醒过程通常根据系统分阶段实施。正如他的同事、Cadence 产品工程总监刘一鹏所解释的那样,像 HiFi 5 这样的 IP 需要“结合传统 DSP 以及处理神经网络本身的能力。
“第一层是检测是否真的有声音,所以这是一个非常轻量级的语音活动检测,”刘说。“如果它检测到语音,那么您就会唤醒下一层处理,称为关键字识别。这可以是非常轻量级的处理。它只是说,‘我听到了一个听起来像我正在听的词。’”
“然后是第三层,一旦你检测到一个触发词,你可能想要唤醒另一个处理层来验证,‘是的,我确实听到了我认为我听到的内容。这实际上是一个非常重的处理负载,”她继续说道,“从那里你继续听,这变成了一个重负载的神经网络处理。
“它可能需要 1 MHz,也可能需要 50 MHz。这真的取决于。”
选择最佳语音 AI 堆栈:“视情况而定”
当谈到 AI 和 ML 技术评估时,这真的取决于。
当然,确定智能音频系统的多少兆赫、多少功耗、关键字检测准确度等关键性能指标因设计而异。Liu 继续解释说,这种多样性使得评估智能语音系统组件甚至 DSP 的可行性变得困难,因为在处理高度专业化的 DSP 时,每秒万亿次操作 (TOPS) 等指标“实际上并不重要”。
“你可以做 1000 TOPS,但所有的操作都是错误的类型。但是您可能只需要 200 MHz 来进行某些类型的处理。或者,如果您编写说明并且一台设备需要 50 MHz 而不是 200 MHz,即使它们具有相同数量的顶部,本质上您拥有更有效的顶部,”她补充道。
不过,最近,MLCommons 已经通过与 EEMBC 合作开发一个新的系统级基准测试来简化评估边缘 AI 组件的过程:MLPerf Tiny Inference。作为 ML Commons 从云到边缘的一系列训练和推理基准中的最新版本,MLPerf Tiny Inference 目前为四个用例提供了标准框架和参考实现:关键字定位、视觉唤醒词、图像分类和异常检测。
MLPerf Tiny 工作负载是围绕预先训练的 32 位浮点参考模型 (FP32) 设计的,哈佛大学边缘计算实验室的博士生兼 MLPerf Tiny 推理工作组联合主席 Colby Banbury 将其识别为当前的“准确性的黄金标准”。但是,MLPerf Tiny Inference 也提供了一个量化的 8 位整数模型 (INT-8)。
MLPerf Tiny 作为系统级基准的不同之处在于它的灵活性,它有助于避免对计算性能进行单点性能评估,例如,允许组织提交 ML 堆栈中的任何组件。这包括编译器、框架或其他任何东西。
但是对于基准测试而言,过于灵活可能是不利的,因为您很快就会得到多个不相关的向量。MLPerf Tiny 通过两个不同的部门(开放式和封闭式)解决了这个问题,它们为提交者和用户提供了针对特定目的或相互衡量 ML 技术的能力。
“MLPerf 通常有这么多规则。它源于灵活性和可比性之间的基准测试中这种不断拉动的因素,”班伯里说。“封闭式基准更具可比性。您采用预先训练的模型,然后您可以根据已概述的某些特定规则以与参考模型等效的方式将其实施到您的硬件上。所以这实际上是硬件平台的一对一比较。”
“但 Tiny ML 的前景需要如此高的效率,因此许多软件供应商甚至硬件供应商都在堆栈中的所有不同点提供价值,”MLPerf Tiny 联合主席继续说道。“因此,为了让人们能够证明他们有更好的模型设计,或者他们可能能够在训练阶段提供更好的数据增强,甚至是不同类型的量化,开放式划分允许你基本上只解决以任何你想要的方式。我们测量准确性、延迟和可选的能量,因此您可以达到产品预期的任何优化点。”
简而言之,封闭部分允许用户根据特定特征评估 ML 组件,而开放部分可用于测量解决方案的一部分或全部。在开放分区中,可以修改模型、训练脚本、数据集和参考实现的其他部分以适应提交要求。
使用经典信号处理清晰聆听
但回到声音。音频 AI 的最终目标是能够完全在边缘执行成熟的自然语言处理 (NLP)。当然,这需要比当今市场准备的更多的处理能力、更多的内存、更多的功率和更多的成本。
“我想说,我们距离真正的自然语言边缘还有两年的时间,”Knowles 的 Shrivastava 说。“我们现在看到成功的地方是低功耗、基于电池的设备,这些设备希望增加语音和语音处理功能。因此,拥有其中一些本地命令或内置功能。
“现在还处于早期阶段,因为你需要大量资源来理解边缘的自然语言,而这仍然是云的领域,”他继续说道。“在过去的五年里,我们仍然没有看到很多自然语言来到边缘。但肯定的是,我们正在将特定于上下文的命令的子集移向边缘。而且我认为我们会看到越来越多的这些命令,因为它们适合某些嵌入式流程。
正在开发的 AI 处理引擎有望更有效地执行语音激活、识别和关键字定位,并在边缘支持更高级、基于自然语言的工作负载。事实上,Knowles 和 Cadence 都在积极开发此类解决方案。
但在中短期内,仍然需要实时做出语音触发验证等本地决策,同时消耗更少的电量。因此,凭借其对流数据进行高效浮点处理的传统,为什么不尝试将传统 DSP 用于新颖的新应用呢?
审核编辑:郭婷
全部0条评论

快来发表一下你的评论吧 !

