

实时数据无处不在,由嵌入多种技术的传感器生成,包括自动驾驶汽车、制造设备和医疗设备。但“实时”对于工程决策的真正意义是什么,更重要的是,如何使用实时数据?
许多工程师可能认为这些数据的主要用途是预测性维护,监控产生所述数据的设备的长期生存能力。虽然这肯定是此类数据的一种潜在用途,但它不是主要用途。实时数据最好由机器学习模型处理,该模型能够在收到数据后尽快分析该数据。然后,这些数据用于生成快速或“实时”发送到数据库、仪表板或设备的见解。
然而,工程师面临的一个共同挑战是处理实时数据,因为原始形式的数据过于混乱,无法进行有效分析。使用机器学习模型来处理这些数据是有帮助的,但更重要的是,工程师必须在将实时数据放入这些模型之前有效地准备好实时数据。
考虑汽车发动机的温度计。从理论上讲,从仪表收集的数据每秒捕获一个温度。但是发动机的温度是由多个传感器测量的,每个传感器的测量速率略有不同——称为采样率或时间步长——必须将其同步到单个数据集中,然后才能通过模型进行分析。那么,工程师应该从哪里开始使用实时数据呢?
尝试同步数据
在宏观层面上,同步数据的目标与同步手表的目标相同——将一个不同的时间与另一个时间对齐,以便它们一起流动。在微观层面上,目标是将多个不同的数据点——本质上是由几个不同步的手表测量的秒数——实时组合到一个数据集中。然而,每个数据点都非常小,而且它们之间的差距如此细小,以至于将它们同步在一起需要仔细准备。
同步实时数据的第一步是对齐。它可以帮助工程师从一个期望的目标开始——一个特定的时间步长或采样率,例如每小时或每 10 秒。但是,实时数据模型通常设计为一次仅处理 1 秒的数据。因此,同步原始设备数据需要创建一个运行在 0 到 1 秒之间的时间向量,时间步长为 0.001 秒,然后“重新采样”数据以匹配新时间。
考虑到这一点,下一步是数据同步艺术的真正所在,因为工程师必须决定如何填充时间不匹配的数据点。这通常通过重新采样原始数据来完成。几种常见的重采样方法包括最近邻、聚合和插值,最佳选择取决于初始时间向量对齐和应用要求。
当工程师不确定数据集之间的时间对齐时,一种常见的解决方案是用恒定值或缺失数据填补空白。这在涉及许多传感器时尤其有用,因为探索和可视化生成的数据可以帮助确定如何继续分析其余数据。如果时间紧密对齐,则可以使用任何提到的重采样方法。如果时间没有紧密对齐,工程师应该聚合或插入数据。
想象一下将每小时数据转换为每日数据。如何在单个数据点中表示 24 小时内的所有数据?在这种情况下,一个合适的例子是数据聚合,比如每日平均值。对于非数字数据,模式、计数或最近邻方法更常见。
在处理实时传感器数据时,尤其是在时间稍微不对齐的情况下,许多工程师使用插值,因为它有助于提供数据趋势的知识,因为要填充的时间空间更少。如果在处理实时传感器数据时点距离较远,则多项式或样条插值法是一种更准确的方法。
下面是使用温度、压力和电流传感器预测设备故障的示例。
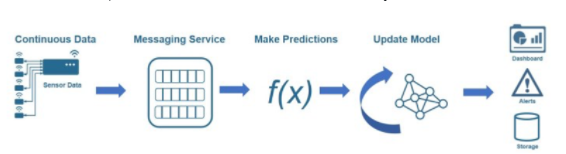
图 1:流式工作流示意图
在此示例中,消息服务处理原始传感器数据,然后将其应用于模型,该模型用于实时生成预测。一旦生成预测,模型就会更新并应用于下一组实时传感器数据。这些结果会不断地、重复地实时发送到仪表板。
实时数据和普通数据的区别
准备实时数据的过程可能听起来很有挑战性。然而,对于工程师来说,内置到大多数数据科学平台的 API 和模块中已经足够普遍了。由于与数据科学平台的共同集成,在遵循此过程时,在使用实时传感器数据构建模型之前,通常需要考虑最少的额外数据准备注意事项。
一个这样的考虑应该是规划一个系统,这意味着在构建任何东西之前捕获所有需求并建立参数。此外,在流程早期构建完整的流式原型也很有帮助,因为它允许工程师在分析实时数据的同时返回调整算法。时间窗口可能是另一个值得考虑的好参数,因为它们通常控制有多少数据进入系统。
在构建模型时,工程师通常会对数据集进行平滑和下采样。对于实时数据,添加了频域,在模型分析数据之前创建了一个要考虑的新参数。一旦原始数据被组织成具有匹配时间的单个数据集,额外的分析就更容易执行。
总体而言,随着自动驾驶汽车和医疗设备以及制造设备和其他设备继续嵌入各种传感器,实时数据将变得更加普遍。随着工程师希望继续提供有价值的基于数据的系统洞察力,有效地导航传感器数据的“实时”方面将非常重要。
审核编辑:郭婷
全部0条评论

快来发表一下你的评论吧 !

