

电子说
一、过滤器模式Pro简介
前已经写过过滤器模式,这里再写一篇有以下几个方面原因:
1、前一章的算法、数据和数据规则没有分离,这里设计一个可用的工具包;
2、C#里面有统一查询语言(LINQ),里面包含数据查询、集合查询、以及排序,这篇文章也来开发一个LabVIEW的统一查询工具包,实现以上功能。
功能包含以上内容:
1、数据查询;
2、集合运算:交集、并集;
3、数据排序:升序和降序;
以上功能可以任意组合。
二、过滤器模式Pro-过滤
下图为我们设计的UML关系类图:
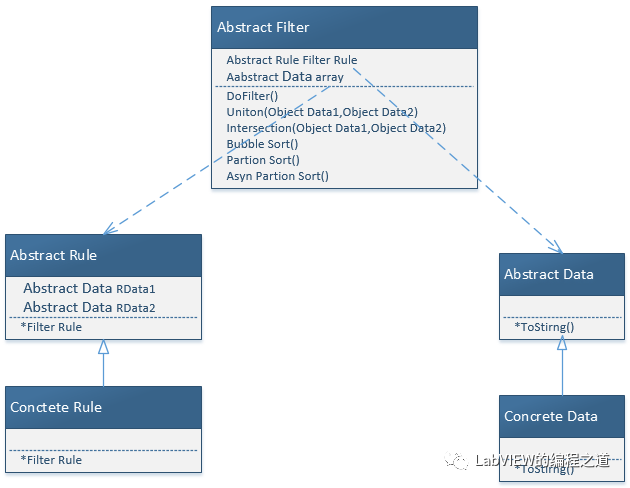
1、Abstract Filter过滤器框架:定义了过滤器过滤的基本规则
2、Abstract Data需要查询的数据类型:只定义的一个tostring用于显示数据
3、Abstract Rule定义了具体数据规则
下面开始编程
1、创建一个工程命名为LLINQ,意思是LabVIEW的LINQ。
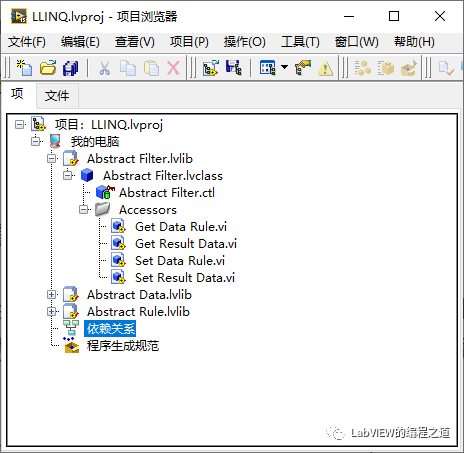
2、创建3个类分别命名为Abstract Filter、Abstract Data和Abstract Rule,在Abstract Filter私有数据中添加Abstract Rule和Abstract Data数组;并创建其数据成员访问。
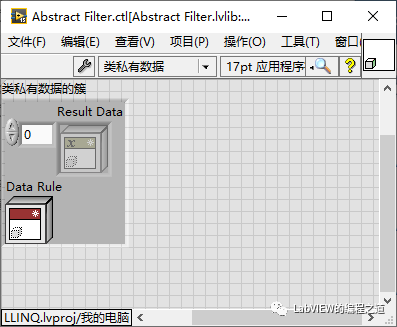
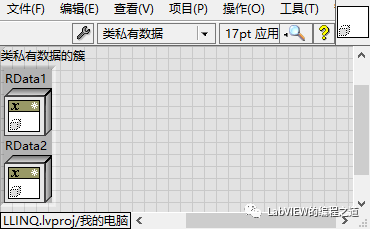
3、在Abstract Rule的私有数据数据中添加两个Abstract Data分别命名为RData1、RData2,并创建其数据成员访问。
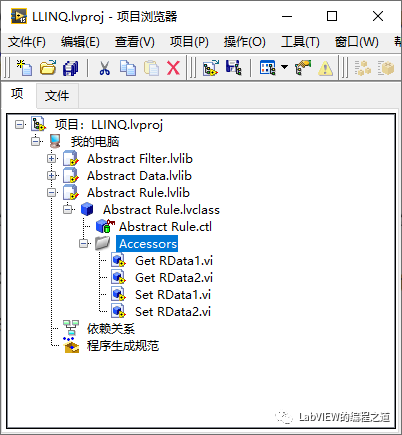
5、在Abstract Rule中创建一个动态VI命名为Filter rule。
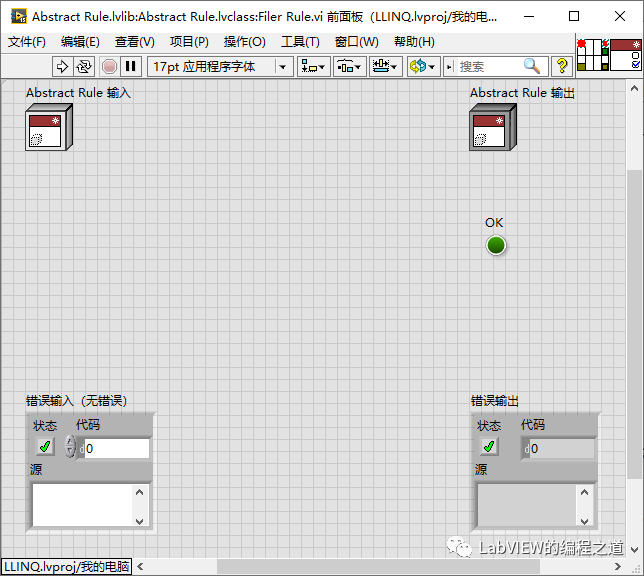
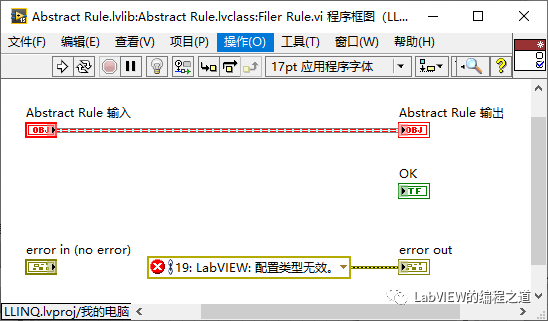
6、在Abstract Filter中添加静态类DoFilter,这个规则比较简单,只要是符合规则就留下,不符合规则就剔除。
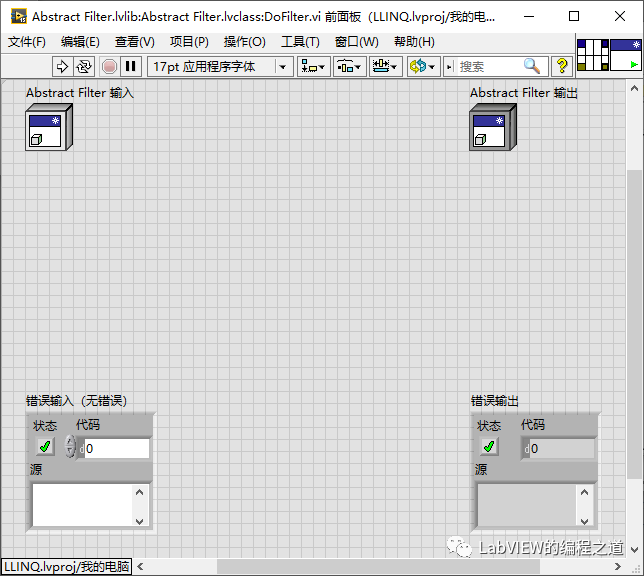
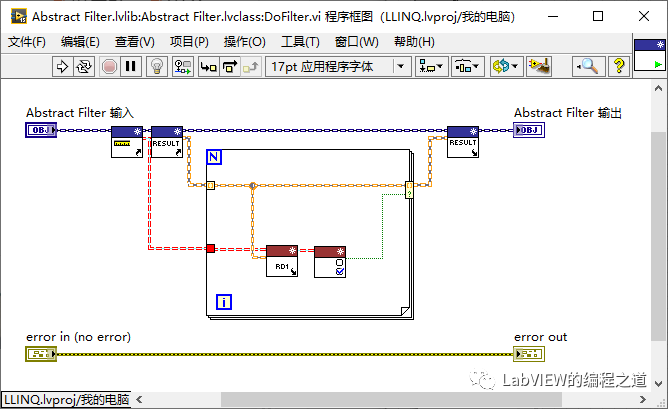
下边写个实际DEMO来演示下过滤模式
6.1、创建VI命名为Filer DEMO
6.2、创建一个类命名为Double data继承至Abstract Data,在私有数据添加一个double类型数据。
6.3、创建一个类命名为Greate The 0.5继承至Abstract rule,重写Filer rule。
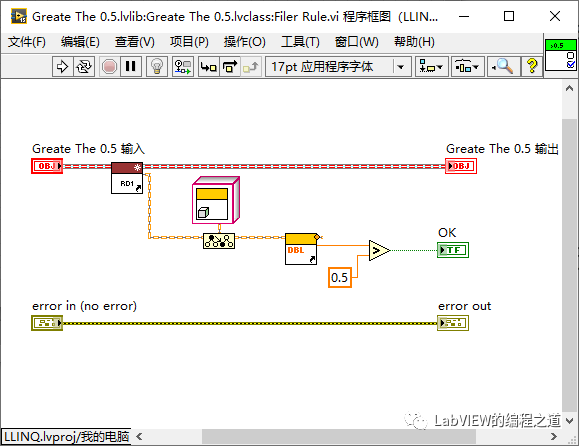
6.4、在Abstrat FIler中添加数据和过滤规则,进行过滤,然后再取出数据
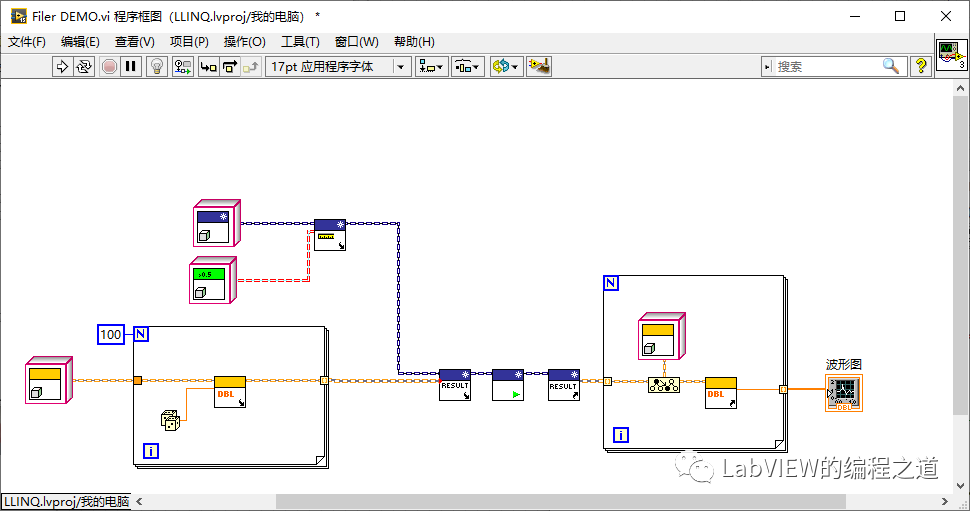
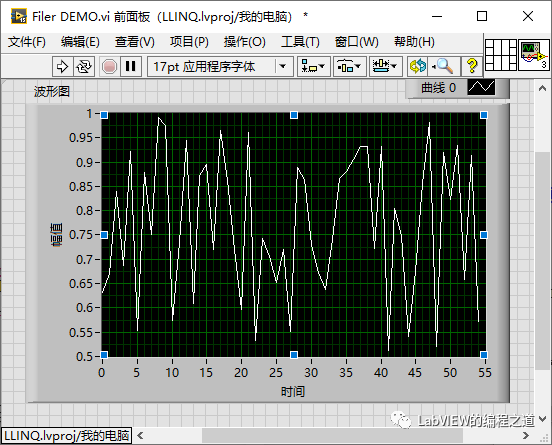
三、过滤器模式Pro-集合运算
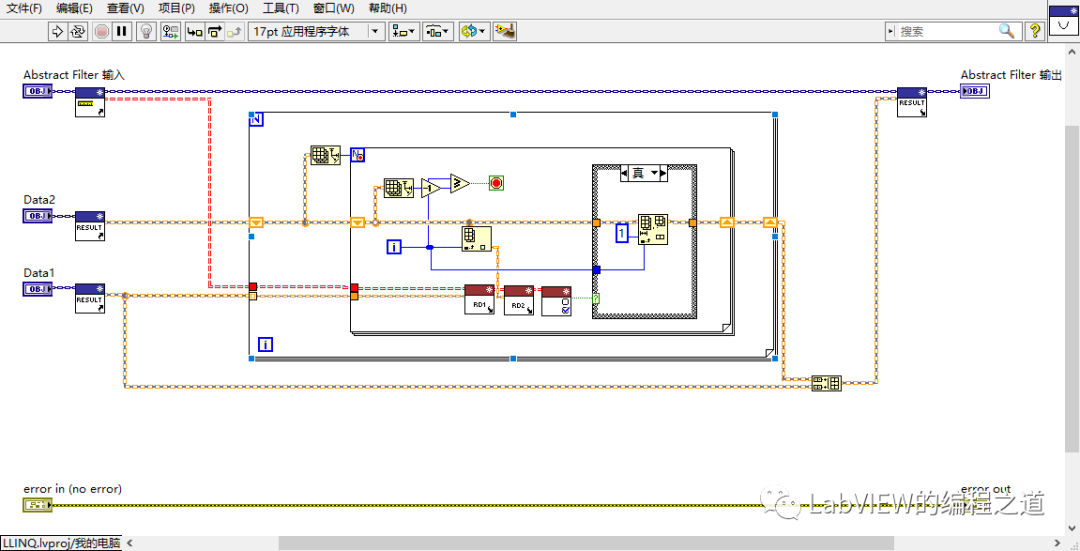
1、并集
在Abstract Filter中创建静态方法Uniton,做法分三步
1.1、设置两个过滤器作为输入;
1.2、找出结合2中与集合1相同的部分并剔除;
1.3、合并剔除后的集合数据并保存到结果数据中。
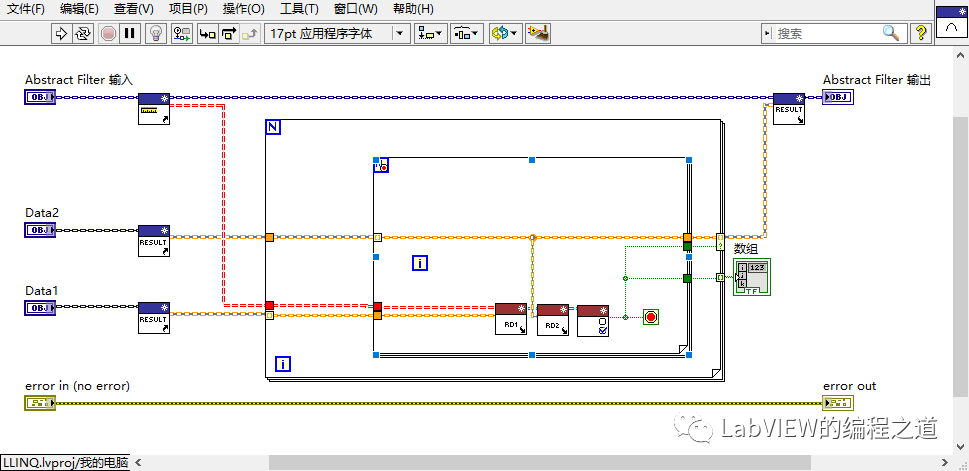
2、交集
在Abstract Filter中创建静态方法Intersection,做法分两步
2.1、设置两个过滤器作为输入;
2.2、取出结合2中与集合1相同的部分,保存到输出结果中。
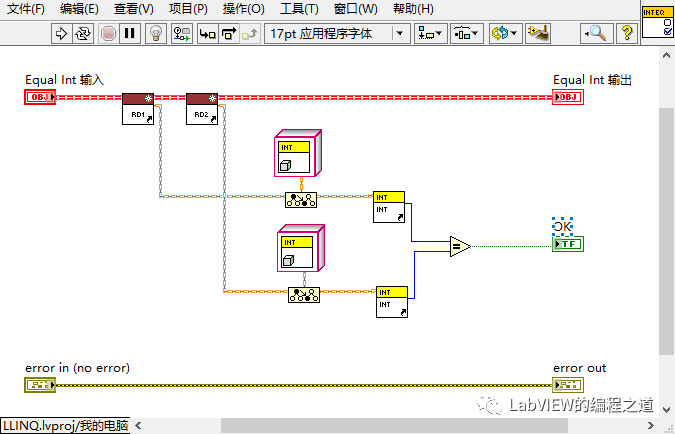
2、集合范例
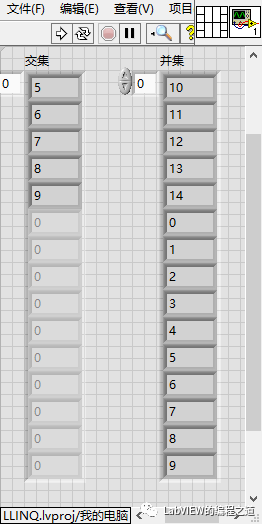
下面是一个两个数组,一个是0--9的整数,一个是5--14的整数,求他们的交集和并集。
先创建一个整类继承至Abstract Rule,私有数据类型为整型,重写数据规则Filer Rule:
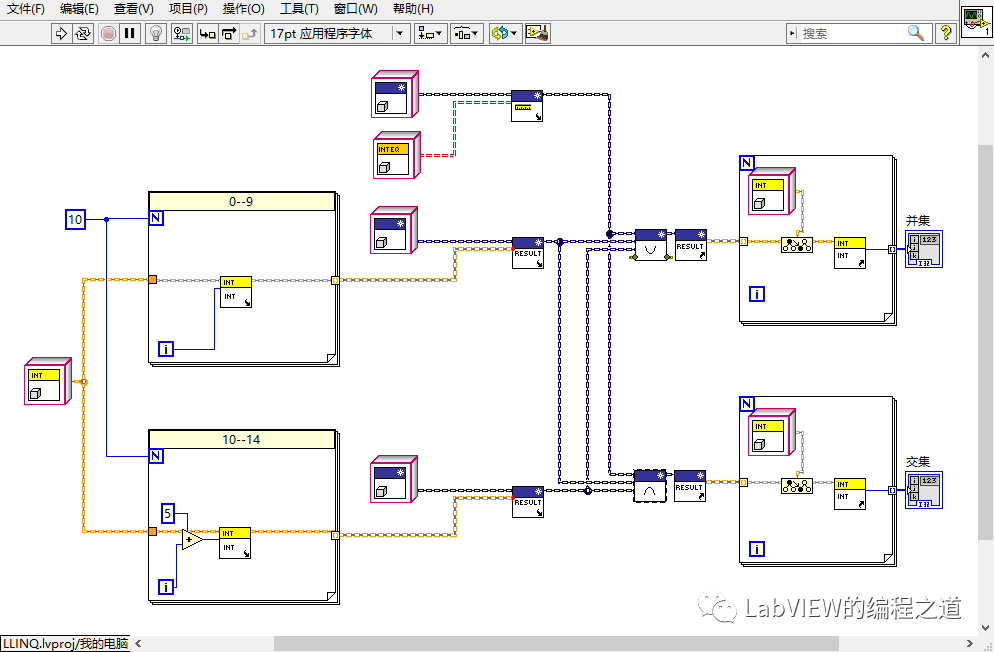
3、下面是具体的使用代码:
4、前面板结果
四、过滤器模式Pro-冒泡排序
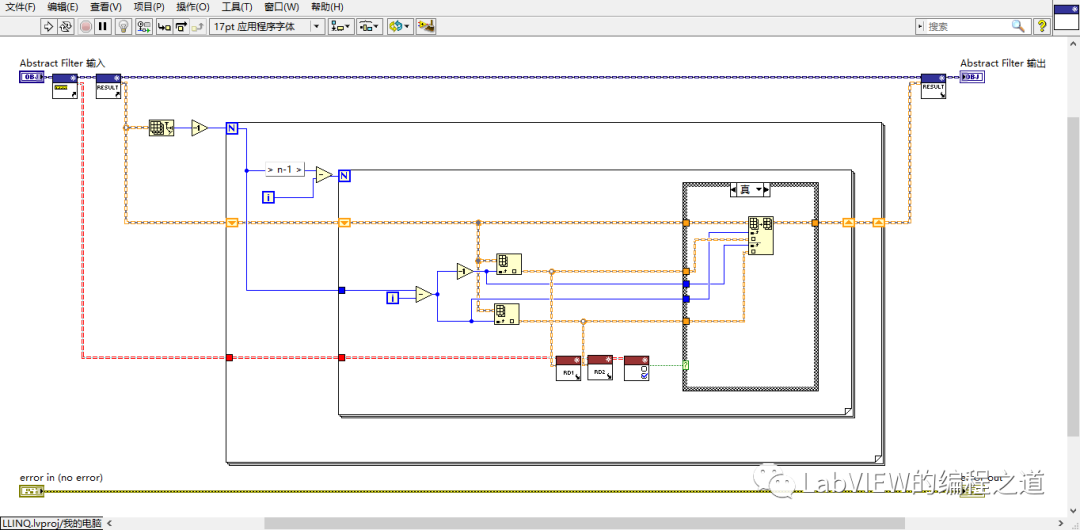
数组排序是一个经常使用的功能,LabVIEW自带的数组排序功能只能对数值类型数据进行排序,那么簇,指定类中特定数据排序呢,每次都需要自己写非常麻烦,影响编程效率。下面写个通用的冒泡排序算法:
从最底部两个元素开始比价,如果上一个元素大于下一个元素就交换位置,然后向上挪一个位置,重复以上操作直到最顶端。最大值就像泡泡浮出水面一样,再从最底端到顶端第二个元素重复上面动作,依次循环
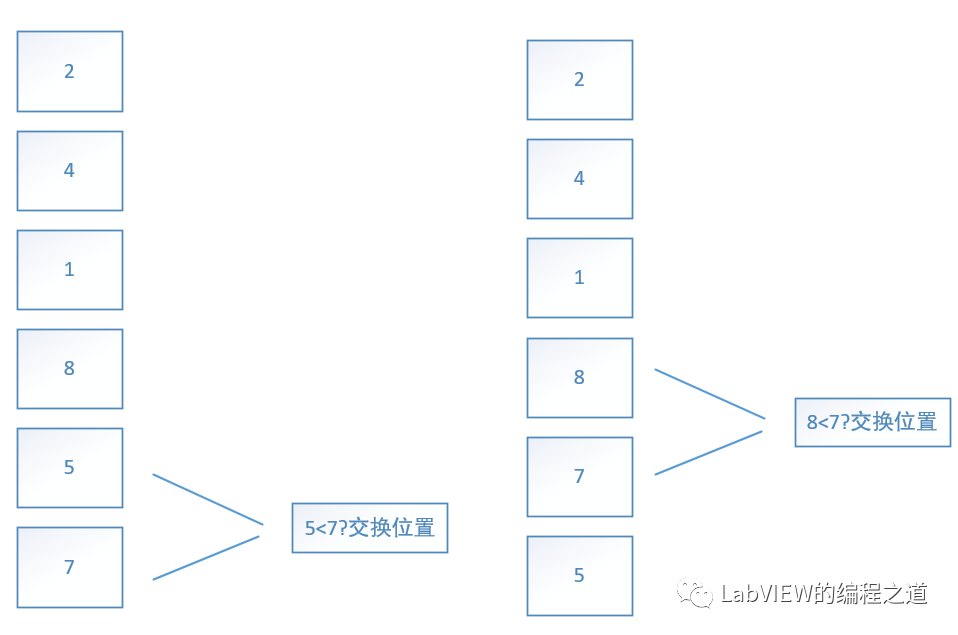
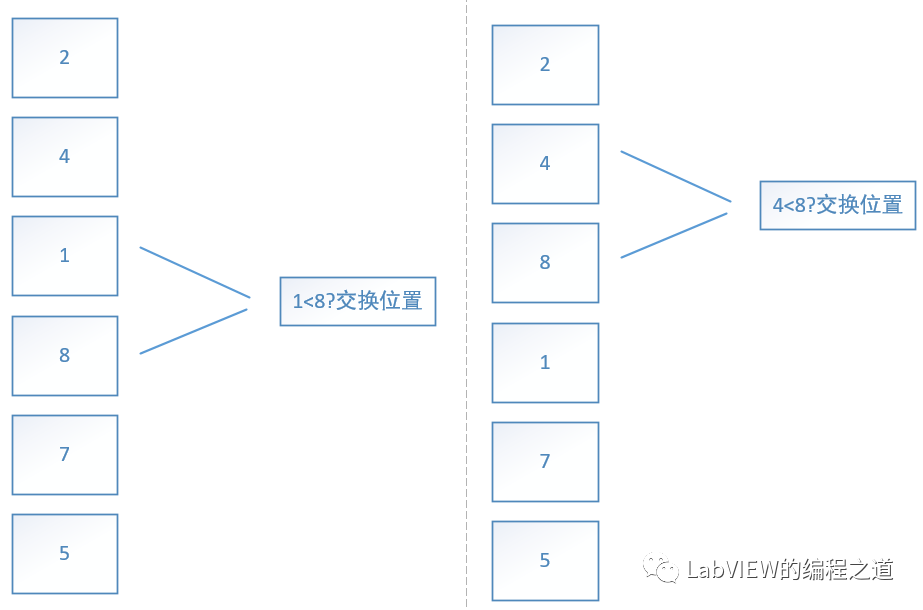
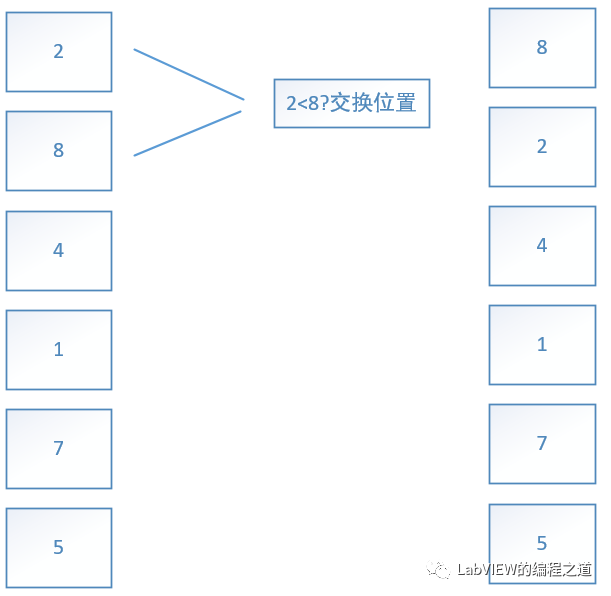
这个是冒泡迭代的位置。
具体编码如下程序框图:
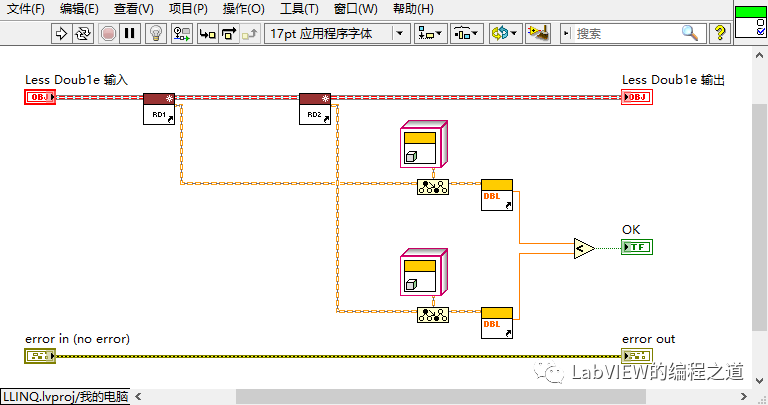
建一个double比较的数据规则
创建个DEMO生成一组随机数看看运行结果:
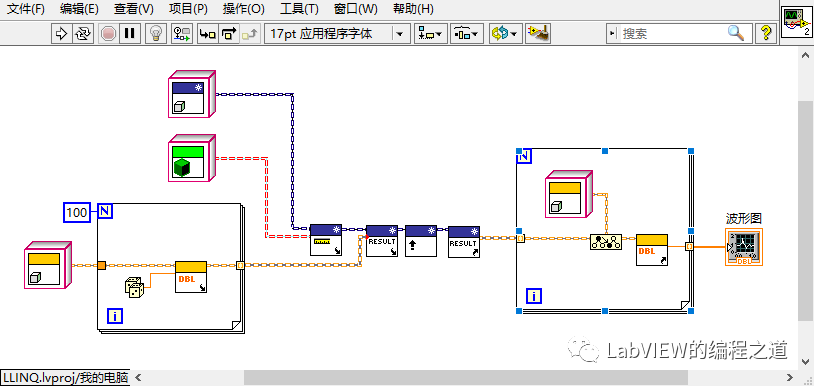
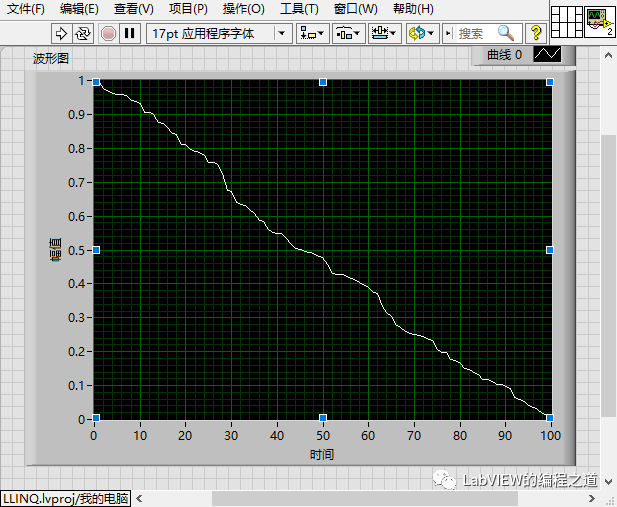
运行下结果达到预期,我们把数据数量改成1000,2000看看运行时间
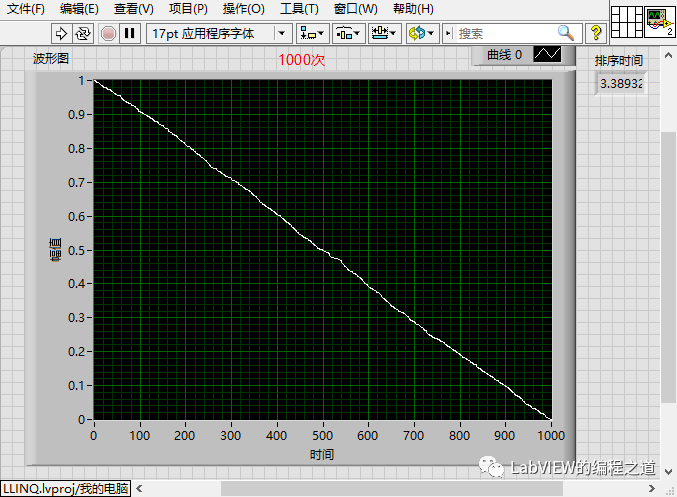
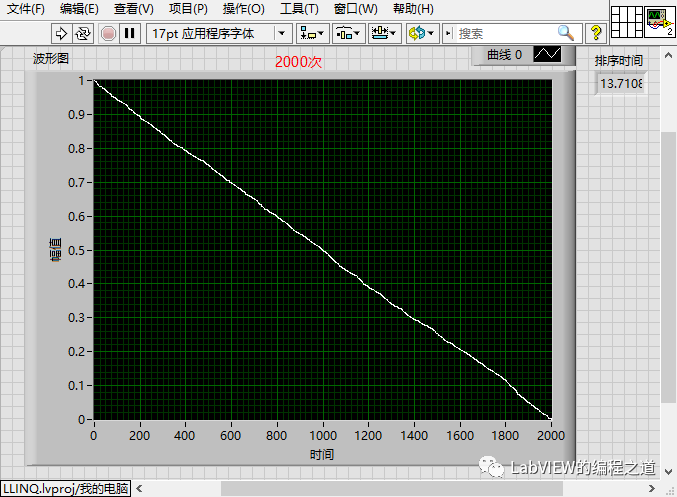
上面可以看到1000次运行时间为3.39秒,2000次运行时间为13.7秒,这个时间感觉太长了,能优化排序算法将时间缩短不?
看下一章的分治排序法。
五、过滤器模式Pro-分治排序
冒泡排序算法的时间复杂度为O(n^2) 空间复杂度为O(1)
我们使用分治排序时间复杂度为O(nlog(n)) 空间复杂度为O(log(n))
简单介绍下原理:
固定第一个数,从最后和最前搜索,当后面大于第一个数,前面小于第一个数时就交换搜到的数据。当两个搜索指针相遇时,就交换第固定数和相遇数。交换后结果为:相遇位置数左边数小,比右边的数大。
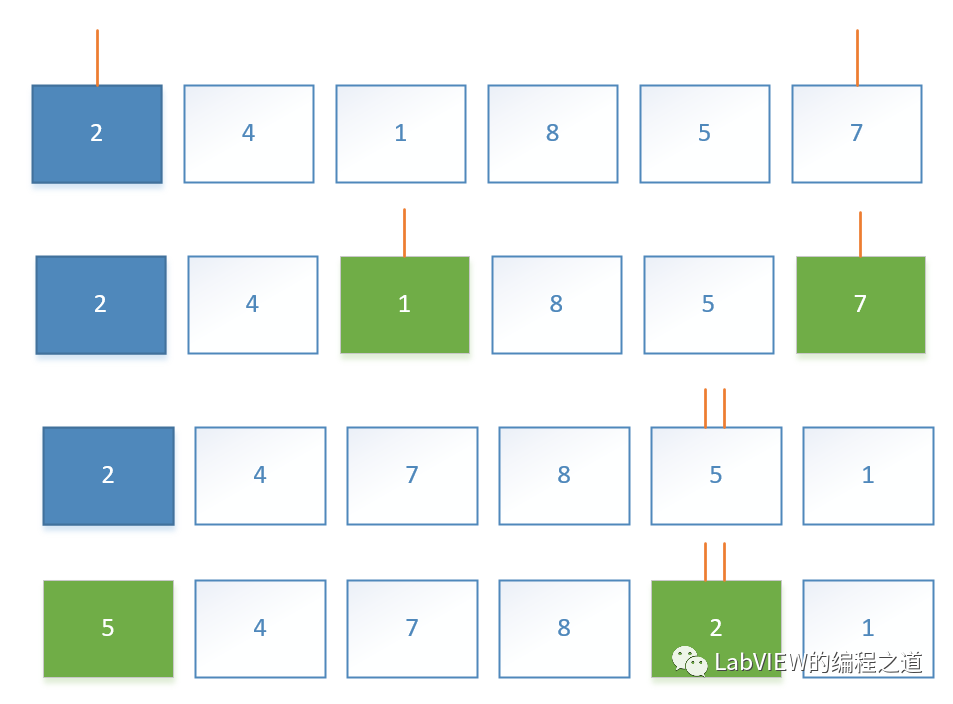
将其按照相遇位置前后分成两组:分别重复上面内容直到分治完成。
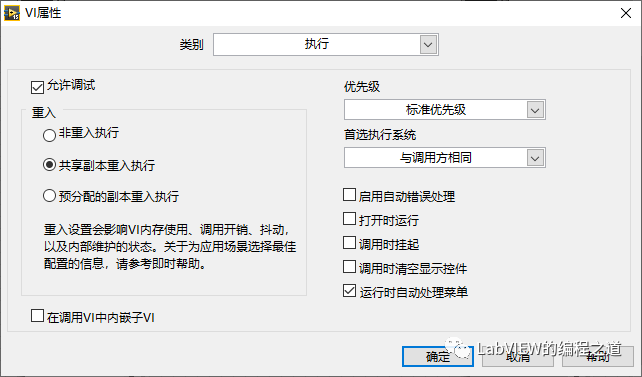
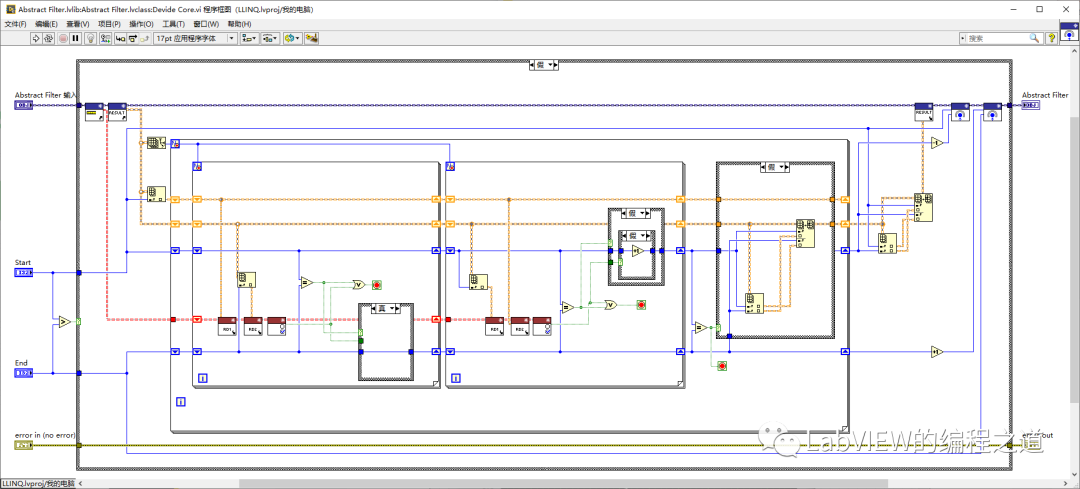
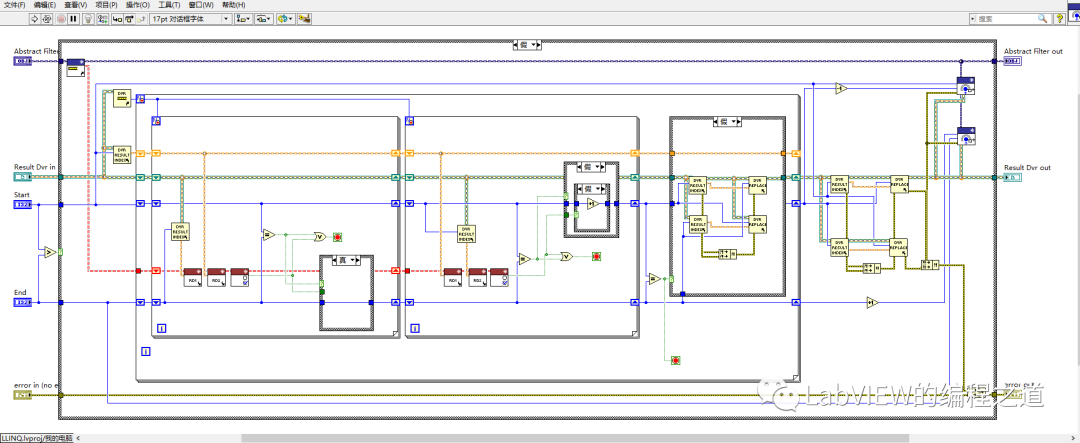
下边开始编写分治算法代码,图中有需要调用相同的算法需要用到递归,我们把主体算法和递归部分分离,创建一个VI命名为Devide Core,VI属性设置如下:
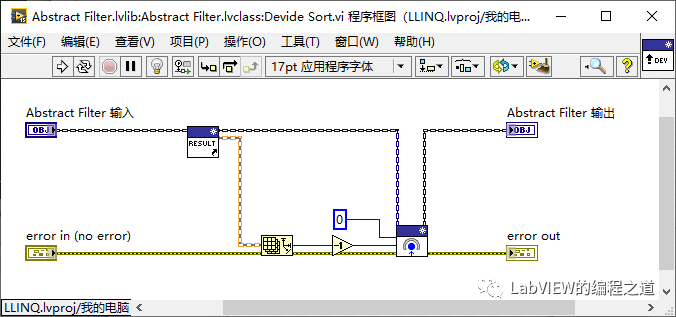
分治核心代码
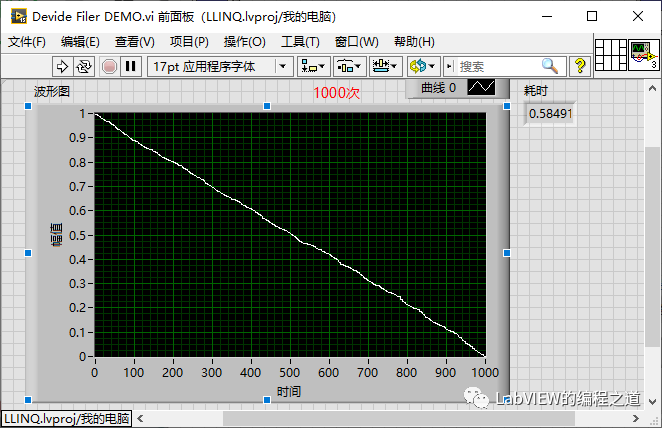
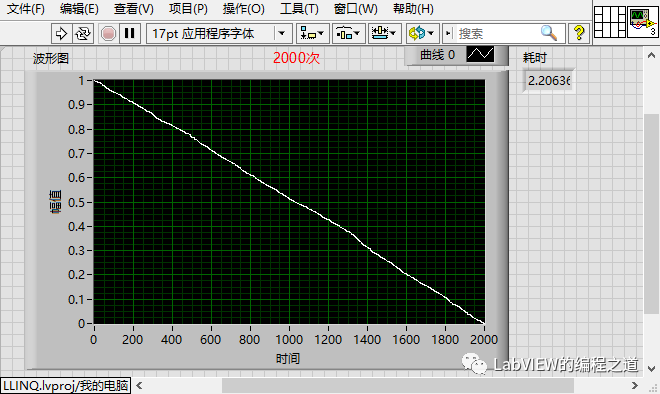
测试后1000次时间为0.58秒,2000次时间为2.20秒,比冒泡排序有了很大的改善,那么有没有更快的优化方案呢?看下边异步分治排序法。

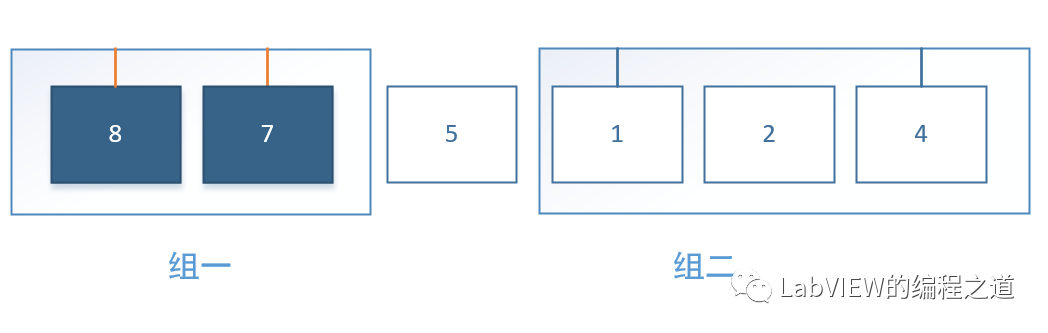
五、过滤器模式Pro-异步分治排序
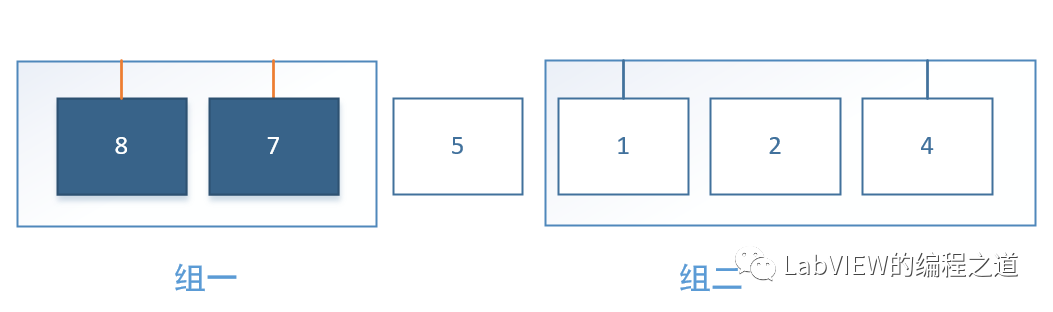
如上图所示,我们第一次分组后,组一执行完后再执行组二,组一和组二的数据互不干扰,那么我们将异步执行组一和组二,以空间换时间。
具体代码改造如下:
1、将数据转换为引用类型;
2、将组一和组二异步执行。
具体代码如下:
异步分治排序算法:
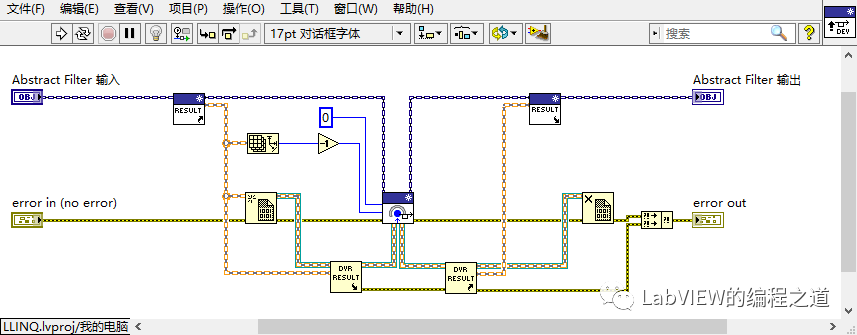
异步分治核心:
测试代码:
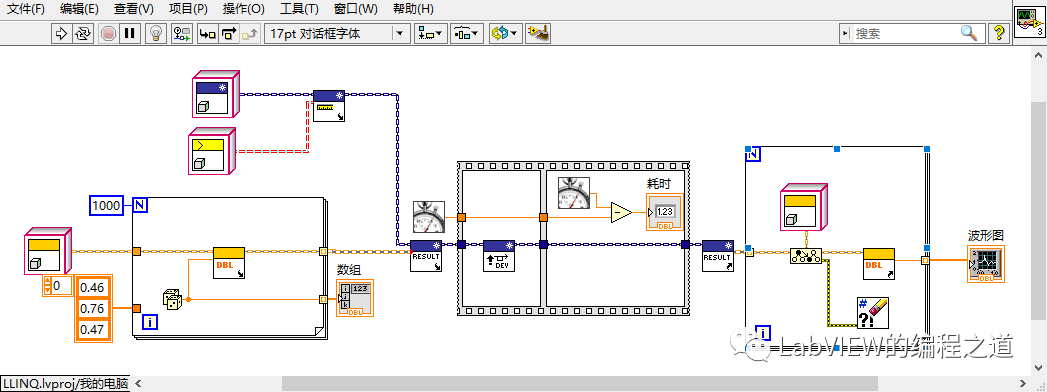
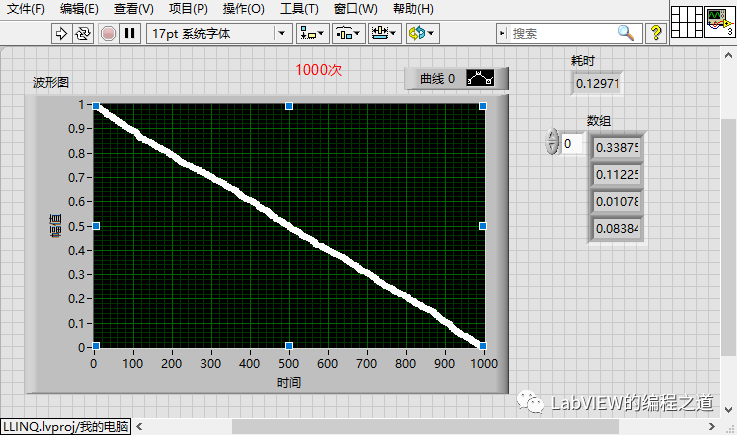
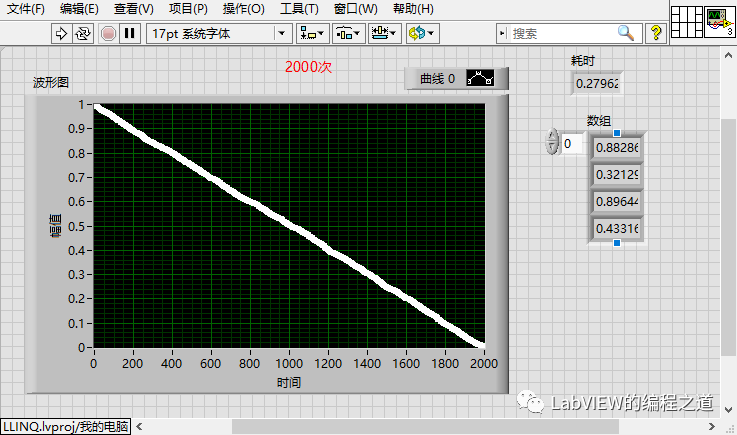
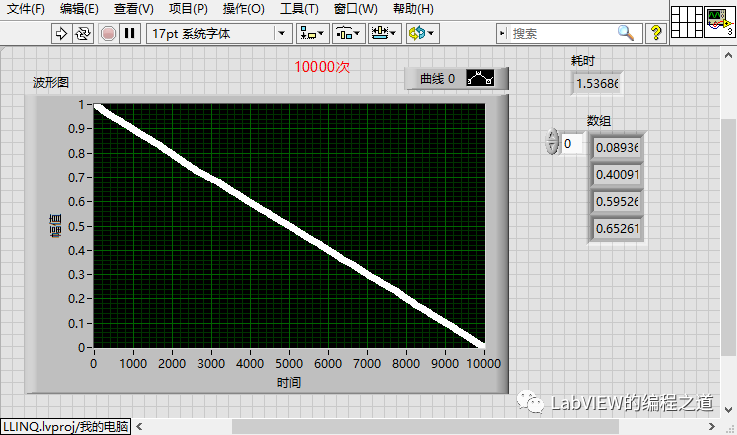
有上面例子可以看出,使用异步分治排序算法,排序速度有了指数级别提升。
审核编辑:郭婷
全部0条评论

快来发表一下你的评论吧 !

