

本文介绍了小组发表于EMNLP 2022的非自回归预训练文本生成模型ELMER,在生成质量与生成效率方面相比于之前的研究具有很大优势。

一、背景
自从GPT-2的出现,预训练语言模型在许多文本生成任务上都取得了显著的效果。这些预训练语言模型大都采用自回归的方式从左到右依次生成单词,这一范式的主要局限在于文本生成的过程难以并行化,因此带来较大的生成延迟,这也限制了自回归模型在许多实时线上应用的广泛部署(例如搜索引擎的查询重写、在线聊天机器人等)。并且,由于训练过程与生成过程存在差异,自回归生成模型容易出现曝光偏差等问题。因此,在这一背景下,许多研究者开始关注非自回归生成范式——所有文本中的单词同时且独立地并行生成。
与自回归模型相比,非自回归模型的生成过程具有并行化、高效率、低延迟等优势,但与此同时,所有单词独立生成的模式使得非自回归模型难以学习单词间依赖关系,导致生成文本质量下降等问题。已有研究提出迭代生成优化、隐变量建模文本映射等方法,但仍然难以生成复杂的文本。受到早期退出技术(early exit)启发,我们提出一个高效强大的非自回归预训练文本生成模型——ELMER,通过在不同层生成不同单词的方式显式建模单词间依赖关系,从而提升并行生成的效果。
二、形式化定义
文本生成的目标是建模输入文本与输出文本 之间的条件概率 。目前常用的三种生成范式为:自回归、非自回归和半非自回归范式。
自回归生成自回归生成模型基于从左到右的方式生成输出文本:
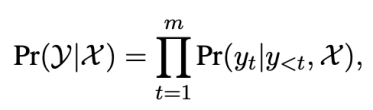
每个单词都依赖于输入文本与之前生成的单词。自回归生成模型只建模了前向的单词依赖关系,依次生成的结构也使得自回归模型难以并行化。目前大部分预训练生成模型均采用自回归方式,包括GPT-2,BART,T5等模型。
非自回归生成非自回归生成模型同时预测所有位置的单词,不考虑前向与后向的单词依赖关系:
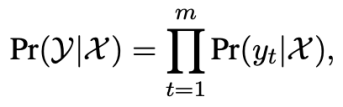
每个单词的生成只依赖于输入文本,这一独立生成假设使得非自回归模型易于并行化,大大提高了文本生成速度。由于不考虑单词依赖,非自回归模型的生成效果往往不如自回归模型。
半非自回归生成半非自回归生成模型介于自回归与非自回归生成之间:
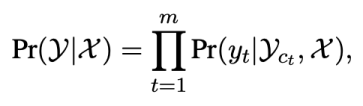
每个单词的生成依赖于输入文本和部分可见上下文,其中采用不同方式平衡生成质量与生成效率。
三、模型
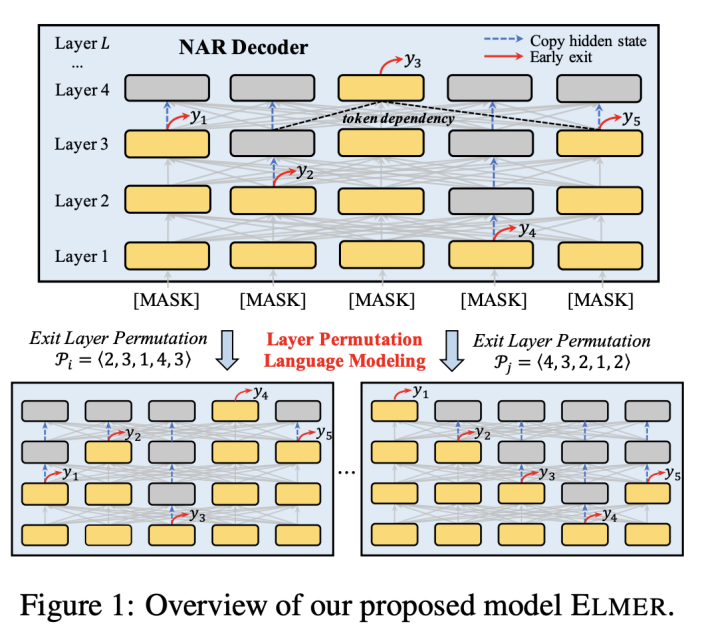
ELMER模型架构如图1所示。基于早期退出机制(early exit),在不同层生成的单词可以建立双向的单词依赖关系。为了预训练ELMER,我们提出了一个用于非自回归生成广泛建模单词依赖的预训练任务——Layer Permutation Language Modeling。
基于早期退出的Transformer非自回归生成
ELMER采用Transformer架构,不同的是我们将解码器中的掩码多头注意力替换为与编码器一致的双向多头注意力用于非自回归生成。特别地,对于数据,输入文本由编码器编码为隐状态,然后,我们将一段完全由“[MASK]”单词组成的序列作为解码器输入,生成目标文本。对于每一个“[MASK]”单词,经过层解码器得到:
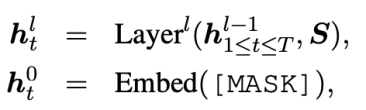
最后,第个单词由最后一层表示计算得到:

之前的非自回归模型需要额外模块预测输出文本的长度,但是,我们通过生成终止单词“[EOS]”动态地确定生成文本的长度,即最终的文本为首单词至第一个终止单词。
一般的Transformer模型都在最后一层生成单词,使用早期退出技术,单词以足够的置信度在低层被生成,那么高层单词的生成可以依赖已生成的低层单词,从而在非自回归生成过程中建模双向的单词依赖关系。特别地,我们在Transformer每一层插入“off-ramp”,其使用每一层隐状态表示预测单词如下:
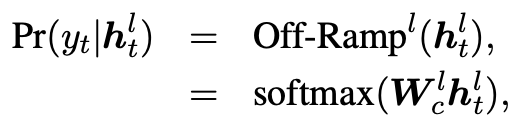
这些“off-ramp”可以独立或者共享参数。与之前的早期退出研究聚焦于句子级别不同,我们的方法关注单词级别的退出。在训练过程中,如果一个单词已经以足够的置信度在第层生成,那么隐状态将不会在高层中进行更新,我们的模型将直接拷贝至高层。
Layer Permutation预训练
为了在预训练中学习多样化的单词依赖关系,我们提出基于早退技术的预训练目标——Layer Permutation Language Modeling (LPLM),对每个单词的退出层进行排列组合。对于长度为的序列,每个单词可以在层的任意一层退出,因此,这一序列所有单词的退出层共有种排列组合。如果模型的参数对于所有组合是共享的,那么每个单词都可以学习到来自所有位置的单词的依赖关系。形式化地,令表示长度为的序列的所有可能的退出层组合,对于任意一个组合,基于LPLM的非自回归文本生成概率可以表示为:
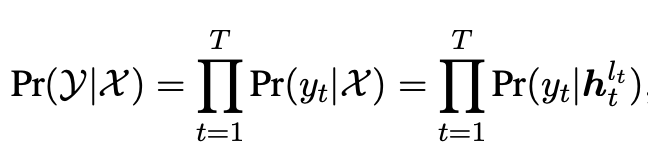
其中模型在解码器第层退出,使用隐状态预测第个单词。
在预训练过程中,对于语料中的每一条文本,我们只采样中退出层组合计算生成概率。传统的早期退出方法需要计算阈值来估计退出层,这对于大规模预训练来说是不方便的,而我们提出的LPLM预训练目标自然而然地避免了对退出层的估计。遵循BART模型的预训练模式,我们将打乱的文本输入模型并采用基于LPLM的非自回归生成方式还原文本,我们主要采用sentence shuffling和text infilling两种打乱方式。
下游微调
经过预训练的非自回归生成模型ELMER可以微调至下游各种文本生成任务。在微调阶段,可以使用小规模的任务数据集为每个生成单词估计其退出层。在论文中,我们主要考虑两种早期退出方式:hard early exit与soft early exit。
1)Hard Early Exit:这是一种最简单直接的早期退出方式。通过设置阈值并计算退出置信度决定模型是否在某层退出结束生成。我们使用生成概率分布的熵来量化单词生成的退出置信度,如下式:
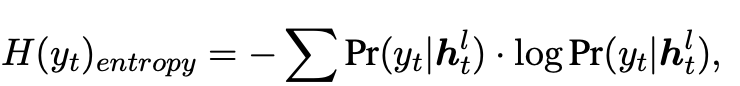
模型生成概率分布的熵越低,意味着生成单词的退出置信度越高。因此,当熵低于事先设定的阈值时,模型将在此层退出并生成单词。
2)Soft Early Exit:上述方法对于每个单词只退出一次并生成,因此会发生错误生成的情况。而soft方法则在每一层都计算单词生成概率,并将中间层生成的单词传递至下一层继续进行计算。特别地,在位置解码器的第层,我们使用第层的off-ramp计算生成单词:
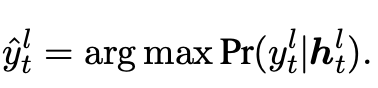
然后,我们将预测单词的向量与当前层的隐状态拼接,经过一个线性层传递至下一层作为新的表示:

与hard方法相比,soft方法在每层预测单词,并将预测结果传递至下一次预测,因此可以起到修正预测的作用。
四、实验
1)预训练设置
我们收集了16G的数据(包括Wikipedia和BookCorpus)作为预训练语料。ELMER采用6层的编码器与解码器,隐藏层维度为768,与大部分自回归(例如BART)与非自回归(BANG)预训练生成模型的base版本一致。我们使用2e-4的学习率从头开始训练模型,批大小为4096。我们采用BART模型的词表,在预训练过程中共享所有层的off-ramp参数,预训练语料中的每条序列采样10种退出层组合进行训练。相关代码与模型已开源至https://github.com/RUCAIBox/ELMER.
2)微调数据集
我们微调ELMER至三种文本生成任务与数据集:XSUM为摘要任务数据集,SQuAD v1.1为问题生成任务数据集,PersonaChat为对话生成任务数据集。
3)基准模型
实验中设置三类基准模型作为对比:1)自回归生成模型:Transformer,MASS,BART和ProphetNet;2)非自回归生成模型:NAT,iNAT,CMLM,LevT和BANG;3)半非自回归生成模型:InsT,iNAT,CMLM,LevT和BANG。
4)评测指标
我们从effectiveness与efficiency两个方面评测模型效果。我们使用ROUGE,BLEU,METEOR和Distinct来评测模型生成文本的effectiveness;设置生成批大小为1并计算每条样本的生成时间来评测模型生成文本的efficiency。
5)实验结果
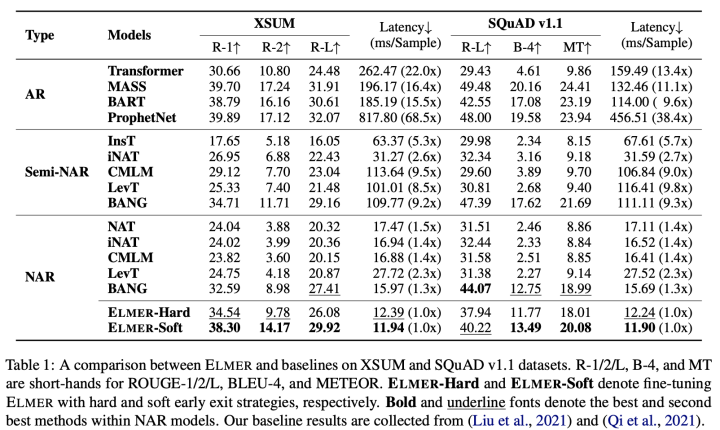
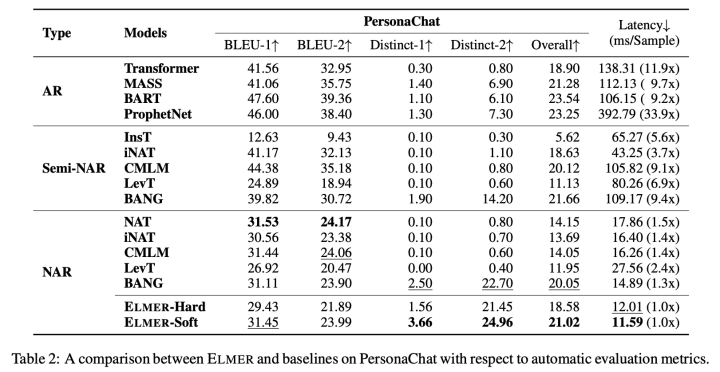
表1与表2展示了在三个任务和数据集上的实验结果。我们的ELMER-soft方法超越了大部分非自回归与半非自回归生成模型,展示出我们的模型在生成文本上的有效性。相比于基准模型,我们的模型采用早期退出技术,可以在并行生成过程中建模单词间依赖关系,保证了生成文本的质量。
除此以外,ELMER取得了与自回归预训练模型相似的结果,并超越了非预训练的Transformer模型,进一步缩小了非自回归生成模型与自回归生成模型在生成质量上的差距。对于对话任务,虽然ELMER在ROUGE,BLEU等指标不如NAT等模型,但非常重要的Distinct指标却表现很好,说明我们方法能够生成较为多样的文本。
最后,在生成文本的效率上,ELMER的生成效率相比自回归模型具有非常大的优势,对比其他非自回归模型如LevT也具有更快的生成速度。
五、结论
我们提出了一个高效强大的非自回归预训练文本生成模型ELMER,通过引入单词级别的早期退出机制,模型可以在并行生成文本的过程中显式建模前后单词依赖关系。更重要的,我们提出了一个新的预训练目标——Layer Permutation Language Modeling,对序列中每个单词的退出层进行排列组合。最后,在摘要、问题生成与对话三个任务上的实验结果表明,我们的ELMER模型无论是生成质量还是生成效率都具有极大优势。
审核编辑 :李倩
全部0条评论

快来发表一下你的评论吧 !

