

多层感知机(Multilayer Perceptron)缩写为MLP,也称作前馈神经网络(Feedforward Neural Network)。 它是一种基于神经网络的机器学习模型,通过多层非线性变换对输入数据进行高级别的抽象和分类。
与单层感知机相比,MLP有多个隐藏层,每个隐藏层由多个神经元组成,每个神经元通过对上一层的输入进行加权和处理,再通过激活函数进行非线性映射。
MLP的输出层通常是一个 softmax 层,用于多分类任务,或者是一个 sigmoid 层,用于二分类任务。
由于它的强大表达能力和灵活性,MLP被广泛应用于各种机器学习任务中。
由于有多个层,参数需要在这些层之间传递。 首先需要实现的就是参数的前向传播,计算过程如下:
在这个过程中,数据和权重是前向传播的主要传播内容。
利用链式法则对网络中的参数进行梯度更新。 在训练神经网络时,通常需要定义一个损失函数(loss function),用于评估模型预测结果与真实标签之间的差距。 反向传播算法的目标就是最小化这个损失函数。
在反向传播过程中,算法首先计算损失函数对最后一层的输出的梯度,然后根据链式法则逐层向前计算各层的梯度,并利用梯度下降法更新网络中的参数。 具体地,算法会先将损失函数对输出的梯度传回网络最后一层,然后依次向前计算各层的梯度。 在计算梯度的过程中,算法会利用反向传播公式来计算当前层的梯度,然后将这个梯度传递到前一层。 在更新网络参数时,算法会根据计算出的梯度和学习率来更新网络中的权重和偏置。
通过不断地反复迭代前向传播和反向传播两个阶段,可以不断地更新网络中的参数,从而逐渐提高模型的性能。
下面是一个Python计算反向传播的示例:
for epoch in range(num_epochs):
for x, y_true in zip(x_train, y_train):
# 前向传播
hidden_layer = np.maximum(0, np.dot(x, self.weights1) + self.bias1) # ReLU激活函数
y_pred = np.dot(hidden_layer, self.weights2) + self.bias2
# 计算损失和梯度,使用均方误差作为损失函数(Mean Squared Error,MSE)
# 对于每一个样本,模型预测出来的输出与实际输出之间的差异会被平方,
# 然后对所有样本的平方差进行求和并除以样本数,即可得到MSE作为模型的损失函数。
loss = np.square(y_true - y_pred).sum()
# 下面复杂的方法用来实现反向传播
# 计算损失函数关于预测输出的导数
d_loss_pred = -2.0 * (y_true - y_pred)
# 计算输出层的梯度,
d_weights2 = np.dot(hidden_layer.reshape(-1, 1), d_loss_pred.reshape(1, -1))
# 计算输出层偏置的梯度,其值等于输出误差
d_bias2 = d_loss_pred
# 计算隐藏层误差,其中 self.weights2.T 代表输出层权重的转置,
# 计算得到的结果是一个行向量,代表每个隐藏层节点的误差。
d_hidden = np.dot(d_loss_pred, self.weights2.T)
# 将隐藏层误差中小于等于 0 的部分置为 0,相当于计算 ReLU 激活函数的导数,
# 这是因为 ReLU 函数在小于等于 0 的部分导数为 0
d_hidden[hidden_layer <= 0] = 0 # ReLU激活函数的导数
# 计算隐藏层权重的梯度,
# 其中 x.reshape(-1, 1) 代表将输入变为列向量,
# d_hidden.reshape(1, -1) 代表将隐藏层误差变为行向量,
# 两者的点积得到的是一个矩阵,
# 这个矩阵的行表示输入的维度(也就是输入节点的个数),
# 列表示输出的维度(也就是隐藏层节点的个数),表示每个输入和每个隐藏层节点的权重梯度。
d_weights1 = np.dot(x.reshape(-1, 1), d_hidden.reshape(1, -1))
# 计算隐藏层偏置的梯度,其值等于隐藏层误差。
d_bias1 = d_hidden
# 更新权重和偏置
self.weights2 -= learning_rate * d_weights2
self.bias2 -= learning_rate * d_bias2
self.weights1 -= learning_rate * d_weights1
self.bias1 -= learning_rate * d_bias1
本示例使用 MNIST 数据集。
import torch
from torchvision import datasets, transforms
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
# 定义ToTensor和Normalize的transform
to_tensor = transforms.ToTensor()
normalize = transforms.Normalize((0.5,), (0.5,))
# 定义Compose的transform
transform = transforms.Compose([
to_tensor, # 转换为张量
normalize # 标准化
])
# 下载数据集
data_train = datasets.MNIST(root="..//data//",
transform=transform,
train=True,
download=True)
data_test = datasets.MNIST(root="..//data//",
transform=transform,
train=False,
download=True)
# 装载数据
data_loader_train = torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,
shuffle=True)
data_loader_test = torch.utils.data.DataLoader(dataset=data_test,
batch_size=64,
shuffle=True)
下面定义一个有三个层的MLP。
对于这个MLP,它接收一个num_i的输入,输出为num_o的预测值。 隐藏层有2层,每层大小为num_h。
层的定义如下:
class MLP(torch.nn.Module):
def __init__(self, num_i, num_h, num_o):
super(MLP, self).__init__()
self.linear1 = torch.nn.Linear(num_i, num_h)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(num_h, num_h) # 2个隐层
self.relu2 = torch.nn.ReLU()
self.linear3 = torch.nn.Linear(num_h, num_o)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.relu2(x)
x = self.linear3(x)
return x
在前向传播时,输入x先通过第一层的线性转换,然后经过第一层隐藏层的激活函数,
再通过第二层的线性转换,再经过第二层隐藏层的激活函数,
最后输出预测值。
本文将使用PyTorch的优化器工具用于反向传播 。
优化器(optimizer)是一个用于更新模型参数的工具,根据训练集的损失函数(loss function)和反向传播算法(backpropagation algorithm)计算梯度,并使用梯度下降算法(gradient descent algorithm)更新模型参数,以最小化损失函数的值。
PyTorch提供了许多常用的优化器,如随机梯度下降法(SGD)、Adam、Adagrad、RMSprop等。
这些优化器使用不同的更新策略,根据不同的训练任务和数据集选择合适的优化器可以提高训练效率和性能。
本文使用和PyTorch优化器的一个实例: torch.optim.Adam(),它使用反向传播算法计算梯度并更新模型的权重,从而调整模型参数以最小化损失函数。
def train(model):
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 设置迭代次数
epochs = 5
for epoch in range(epochs):
sum_loss = 0
train_correct = 0
for data in data_loader_train:
# 获取数据和标签
inputs, labels = data # inputs 维度:[64,1,28,28]
# 将输入数据展平为一维向量
inputs = torch.flatten(inputs, start_dim=1) # 展平数据,转化为[64,784]
# 计算输出
outputs = model(inputs)
# 将梯度清零
optimizer.zero_grad()
# 计算损失函数
loss = cost(outputs, labels)
# 反向传播计算梯度
loss.backward()
# 使用优化器更新模型参数
optimizer.step()
# 返回 outputs 张量每行中的最大值和对应的索引,1表示从行维度中找到最大值
_, id = torch.max(outputs.data, 1)
# 将每个小批次的损失值 loss 累加,用于最后计算平均损失
sum_loss += loss.data
# 计算每个小批次正确分类的图像数量
train_correct += torch.sum(id == labels.data)
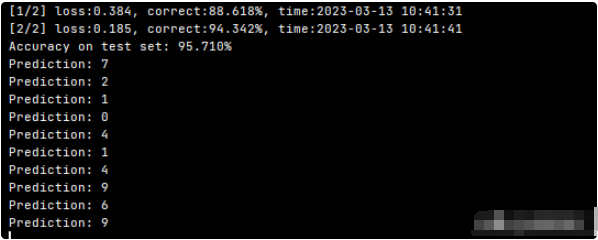
print('[%d/%d] loss:%.3f, correct:%.3f%%, time:%s' %
(epoch + 1, epochs, sum_loss / len(data_loader_train),
100 * train_correct / len(data_train),
time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())))
model.eval()
# 测试模型
def test(model, test_loader):
test_correct = 0
for data in test_loader:
inputs, lables = data
inputs, lables = Variable(inputs).cpu(), Variable(lables).cpu()
inputs = torch.flatten(inputs, start_dim=1) # 展并数据
outputs = model(inputs)
_, id = torch.max(outputs.data, 1)
test_correct += torch.sum(id == lables.data)
print(f'Accuracy on test set: {100 * test_correct / len(data_test):.3f}%')
在神经网络模型的推断(inference)阶段中,我们不需要进行反向传播,也不需要计算梯度,使用 with torch.no_grad(): 上下文管理器可以有效地减少内存消耗和计算时间
def predict(model, data):
model.eval()
with torch.no_grad():
output = model(data)
pred = output.data.max(1, keepdim=True)[1]
return pred
1234567
import torch
from torchvision import datasets, transforms
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
# 定义ToTensor和Normalize的transform
to_tensor = transforms.ToTensor()
normalize = transforms.Normalize((0.5,), (0.5,))
# 定义Compose的transform
transform = transforms.Compose([
to_tensor, # 转换为张量
normalize # 标准化
])
# 下载数据集
data_train = datasets.MNIST(root="..//data//",
transform=transform,
train=True,
download=True)
data_test = datasets.MNIST(root="..//data//",
transform=transform,
train=False,
download=True)
# 装载数据
data_loader_train = torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,
shuffle=True)
data_loader_test = torch.utils.data.DataLoader(dataset=data_test,
batch_size=64,
shuffle=True)
class MLP(torch.nn.Module):
def __init__(self, num_i, num_h, num_o):
super(MLP, self).__init__()
self.linear1 = torch.nn.Linear(num_i, num_h)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(num_h, num_h) # 2个隐层
self.relu2 = torch.nn.ReLU()
self.linear3 = torch.nn.Linear(num_h, num_o)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.relu2(x)
x = self.linear3(x)
return x
def train(model):
# 损失函数,它将网络的输出和目标标签进行比较,并计算它们之间的差异。在训练期间,我们尝试最小化损失函数,以使输出与标签更接近
cost = torch.nn.CrossEntropyLoss()
# 优化器的一个实例,用于调整模型参数以最小化损失函数。
# 使用反向传播算法计算梯度并更新模型的权重。在这里,我们使用Adam优化器来优化模型。model.parameters()提供了要优化的参数。
optimizer = torch.optim.Adam(model.parameters())
# 设置迭代次数
epochs = 2
for epoch in range(epochs):
sum_loss = 0
train_correct = 0
for data in data_loader_train:
inputs, labels = data # inputs 维度:[64,1,28,28]
# print(inputs.shape)
inputs = torch.flatten(inputs, start_dim=1) # 展平数据,转化为[64,784]
# print(inputs.shape)
outputs = model(inputs)
optimizer.zero_grad()
loss = cost(outputs, labels)
loss.backward()
optimizer.step()
_, id = torch.max(outputs.data, 1)
sum_loss += loss.data
train_correct += torch.sum(id == labels.data)
print('[%d/%d] loss:%.3f, correct:%.3f%%, time:%s' %
(epoch + 1, epochs, sum_loss / len(data_loader_train),
100 * train_correct / len(data_train),
time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())))
model.train()
# 测试模型
def test(model, test_loader):
model.eval()
test_correct = 0
for data in test_loader:
inputs, lables = data
inputs, lables = Variable(inputs).cpu(), Variable(lables).cpu()
inputs = torch.flatten(inputs, start_dim=1) # 展并数据
outputs = model(inputs)
_, id = torch.max(outputs.data, 1)
test_correct += torch.sum(id == lables.data)
print(f'Accuracy on test set: {100 * test_correct / len(data_test):.3f}%')
# 预测模型
def predict(model, data):
model.eval()
with torch.no_grad():
output = model(data)
pred = output.data.max(1, keepdim=True)[1]
return pred
num_i = 28 * 28 # 输入层节点数
num_h = 100 # 隐含层节点数
num_o = 10 # 输出层节点数
batch_size = 64
model = MLP(num_i, num_h, num_o)
train(model)
test(model, data_loader_test)
# 预测图片,这里取测试集前10张图片
for i in range(10):
# 获取测试数据中的第一张图片
test_image = data_test[i][0]
# 展平图片
test_image = test_image.flatten()
# 增加一维作为 batch 维度
test_image = test_image.unsqueeze(0)
# 显示图片
plt.imshow(test_image.view(28, 28), cmap='gray')
plt.show()
pred = predict(model, test_image)
print('Prediction:', pred.item())
全部0条评论

快来发表一下你的评论吧 !

