

电子说
Python在IC中的应用,主要处理的对象以文本为主,但在某些的情况下,文本文件非常巨大,比如上G的文件。
这个时候,利用gvimdiff,tkdiff对文件的比对是比较慢甚至卡的,Python有很强大的数据处理能力,这里使用zip命令可以非常高效的进行文件比对。
下面脚本参考:
用法:./diff.py test1.log test2.log
./diff.py test1.log test2.log [NOTE]:Found (diff/total): 564/5664 different lines [NOTE]:File is different [NOTE]:All different lines are saved in file: diffout.rpt
不同行内容输出到diffout.rpt文件中;
#!/tools/python-3.6.12/bin/python3.6
# -*- coding: UTF-8 -*-
import os
import sys
if len(sys.argv) > 1:
file1 = sys.argv[1]
file2 = sys.argv[2]
else:
print("[ERROR] ====== Please enter two file_path")
print("[Usage]: Python script.py ")
sys.exit()
def compare_files(file1, file2):
total_lines = 0
different_lines = 0
with open(file1, 'r') as f1, open(file2, 'r') as f2,open('diffout.rpt', 'w') as f_out:
# 逐行比较两个文件
for i, (line1, line2) in enumerate(zip(f1, f2)):
if line1 != line2:
f_out.write('row ' + str(i+1) + ' is different:
')
f_out.write(' file1:' + line1.rstrip() + '
')
f_out.write(' file2:' + line2.rstrip() + '
')
different_lines += 1
total_lines += 1
if total_lines == 0:
print('Both files are empty')
if different_lines == 0:
print('File is same')
else:
print('[NOTE]:Found (diff/total): {}/{} different lines'.format(different_lines, total_lines))
print('[NOTE]:File is different')
print('[NOTE]:All different lines are saved in file: diffout.rpt')
compare_files(file1, file2)
其中简单说明两个函数:enumerate()和zip(f1, f2)
enumerate() 是 Python 内置函数,它接受一个可迭代对象(如列表、元组、字符串等)作为输入,返回一个枚举对象。
这个枚举对象包含每个元素的索引和值,可以用来遍历序列时获取当前元素的索引。
以下是一个使用 enumerate() 函数的示例:
fruits = ['apple', 'banana', 'cherry'] for i, fruit in enumerate(fruits): print(i, fruit)
在上面的代码中,enumerate() 函数将 fruits 列表转换为一个枚举对象,遍历该对象时,每个元素会被拆分成两部分,一部分是索引,一部分是值。
输出结果:
0 apple 1 banana 2 cherry
在循环体内,我们可以使用 i 变量来访问当前元素的索引,使用 fruit 变量来访问当前元素的值。
zip(f1, f2) 是将两个可迭代对象 f1 和 f2 中的对应元素一一配对,生成一个新的迭代器;
在比较文件的过程中,zip() 函数可以用来同时遍历两个文件对象 f1 和 f2,逐行比较它们的内容。
这里再额外提一个利用difflib 模块进行文件比对
使用 difflib 模块进行文件比对可以得到更详细的文件差异信息。difflib 模块提供了多种比对算法和函数,可以用来比较文本文件、代码文件等;
使用 difflib.HtmlDiff() 类来生成差异信息的 HTML 格式。
下面是一个示例代码,它比对两个文件并将差异信息以 HTML 格式输出到文件difflib.html 中
#!/tools/python-3.6.12/bin/python3.6
# -*- coding: UTF-8 -*-
import os
import sys
import difflib
if len(sys.argv) > 1:
file1 = sys.argv[1]
file2 = sys.argv[2]
else:
print("[ERROR] ====== Please enter two file_path")
print("[Usage]: Python script.py ")
sys.exit()
def diff_files(file1, file2, output_file):
# 读取两个文件的内容
with open(file1, 'r') as f1, open(file2, 'r') as f2:
text1 = f1.read()
text2 = f2.read()
# 生成差异信息的 HTML 格式
d = difflib.HtmlDiff()
html = d.make_file(text1.splitlines(), text2.splitlines())
# 将 HTML 内容写入文件
with open(output_file, 'w') as f:
f.write(html)
print("
Diff completed.")
if __name__ == '__main__':
diff_files(file1, file2, 'difflib.html')
上面的代码中,使用 difflib.HtmlDiff() 类的 make_file() 方法生成差异信息的 HTML 格式。
注意要使用 splitlines() 方法将文本转换为行列表。
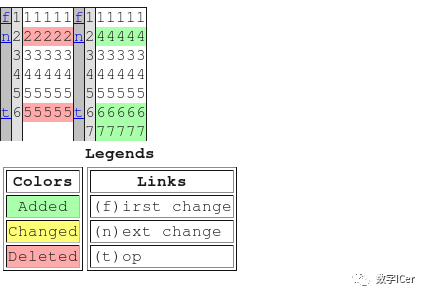
生成的 HTML 文件中,差异信息会以表格形式呈现,每一行的左侧显示行号,右侧显示该行的内容。
这种格式的输出相对于纯文本格式的输出更容易阅读和理解,特别是在需要比对较长文本时,能够提高比对效率和结果的准确性。
审核编辑:刘清
全部0条评论

快来发表一下你的评论吧 !

