

RDMA 技术简介
不过,相对于以太网方案,RDMA 方案对网卡提出了新的要求,主要有两点。
• 能够解析页表:由于应用程序申请的数据缓存一般都是虚拟地址连续而物理地址不连续的,因此要求硬件有解析页表的能力,能够访问物理地址不连续的缓存。注意,此处所说的页表是软件专门为 RDMA 网卡建立的,不是 MMU 访问的页表。
• 能够封装和解析数据包:网卡需要按照协议,在发送数据前加上协议报头与校验和,并在接收数据后将其剥离。
13.2 RDMA 的优势
人们经常用 100M、1G、10G、25G、100G(单位为 bit/s)等描述网卡支持的最大带宽(常被称为速率),无论是以太网卡和 RDMA 网卡都是如此。但如果同为 100G 带宽,除了降低了 CPU 的工作负载,单纯从网络性能方面考虑,RDMA 网卡相比以太网卡的优势在哪里呢?
先考虑使用以太网卡的情况。假设应用程序从时刻 0 开始产生数据(Data),之后每 1ns(纳秒)持续产生 1 个 Data(100 位),每个 Data 产生之后的每个操作步骤都花费 1ns,可以得到如图 13-4 所示的数据流水线模型。
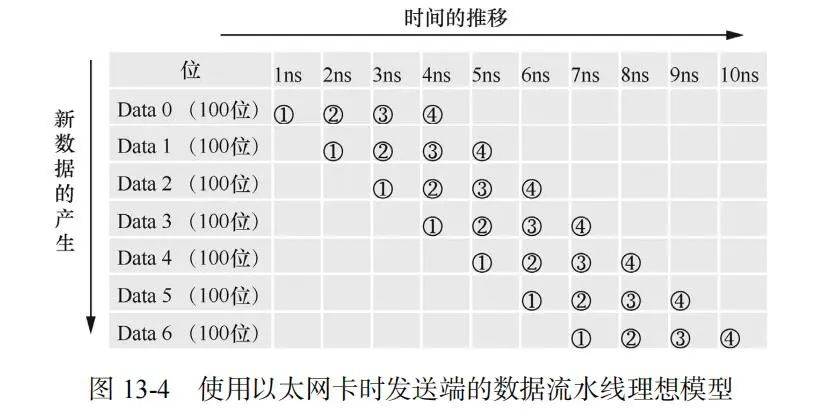
对应图 13-4 中的编号,每个 Data 的操作步骤如下。
① 应用程序申请用户空间缓存并写入数据。
② 内核协议栈申请内核空间缓存,并将数据从用户空间缓存复制到内核空间缓存。
③ 驱动程序操作网卡把数据从内核空间缓存通过 DMA 复制到网卡内部缓存。
④ 网卡把数据发送到对端网卡。
理论上只要满足如下三个条件就可以实现 100Gbit/s 的发送速率。
• ①②③④每一步的操作时长都小于 1ns(实际应该是 0.93ns,但不影响理解数据流水线模型的概念),即每一步都足够快。
• 每隔 1ns 就有新的数据产生,即有源源不断的数据。
• 从第一个 Data 处理的最后一步(第 4ns)之后开始计算带宽,即合适的计算时机。
需要注意的是,这种模式下每个 Data 需要 4ns 发送到对端网卡,也就是说对端网卡当前接收到的是 4ns 之前产生的数据。
基于同样的假设,可以得到 RDMA 网卡的数据流水线模型,如图 13-5 所示。
对应图 13-5 中的编号,每个 Data 的操作步骤如下:
② 应用程序向用户空间缓存写入数据。
② 驱动程序操作网卡把数据从用户空间缓存通过 DMA 复制到网卡内部缓存。
③ 网卡把数据发送到对端网卡。
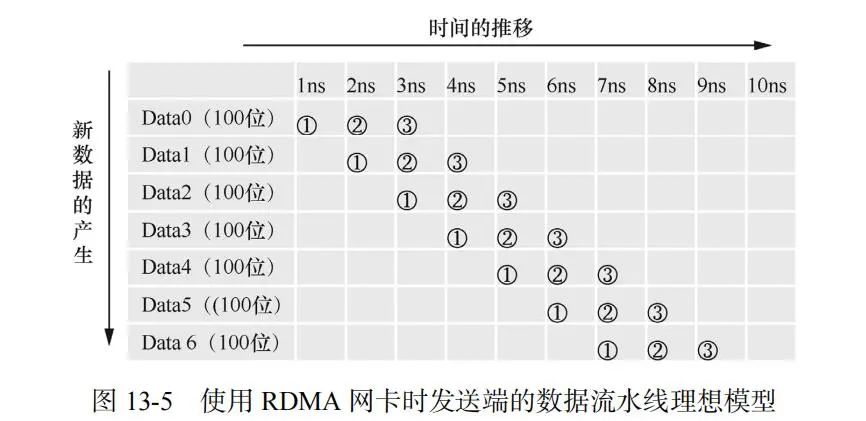
同样地,只要满足前文提到的三个条件,就可以实现 100Gbit/s 的发送速率。只是最后一个条件的计算时间可以提前 1ns,从第 3ns 开始算。在此可以看出 RDMA 方案的优势:每个Data 只需要 3 ns 就可以到达对端网卡(即具有更低的时延)。
通信领域出现率最高的性能指标就是带宽和时延。简单来说,所谓带宽是指单位时间内能够传输的数据量(比如 100Gbit/s),而时延指的是数据从本端发出到被对端接收所消耗的时间。
相比传统以太网,RDMA 技术实现了更低的时延,所以 RDMA 能够在很多对时延要求较高的场景中(比如分布式神经网络多个计算节点间的数据同步)得以发挥作用。
审核编辑:刘清
全部0条评论

快来发表一下你的评论吧 !

