

下面看一个特别重要的框架,也可以称为是拥塞控制引擎,如下结构体所示, tcp_congestion_ops描述了一套拥塞控制算法所需要支持的操作 。这个框架定义了一些钩子函数,Linux内核中不同的拥塞控制算法根据算法思想实现以下钩子函数,然后进行注册即可完成拥塞控制算法的设计。
struct tcp_congestion_ops {
struct list_head list;
u32 key;
u32 flags;
/* initialize private data (optional) */
void (*init)(struct sock *sk);
/* cleanup private data (optional) */
void (*release)(struct sock *sk);
/* return slow start threshold (required) */
u32 (*ssthresh)(struct sock *sk);
/* do new cwnd calculation (required) */
void (*cong_avoid)(struct sock *sk, u32 ack, u32 acked);
/* call before changing ca_state (optional) */
void (*set_state)(struct sock *sk, u8 new_state);
/* call when cwnd event occurs (optional) */
void (*cwnd_event)(struct sock *sk, enum tcp_ca_event ev);
/* call when ack arrives (optional) */
void (*in_ack_event)(struct sock *sk, u32 flags);
/* new value of cwnd after loss (required) */
u32 (*undo_cwnd)(struct sock *sk);
/* hook for packet ack accounting (optional) */
void (*pkts_acked)(struct sock *sk, const struct ack_sample *sample);
/* suggest number of segments for each skb to transmit (optional) */
u32 (*tso_segs_goal)(struct sock *sk);
/* returns the multiplier used in tcp_sndbuf_expand (optional) */
u32 (*sndbuf_expand)(struct sock *sk);
/* call when packets are delivered to update cwnd and pacing rate,
* after all the ca_state processing. (optional)
*/
void (*cong_control)(struct sock *sk, const struct rate_sample *rs);
/* get info for inet_diag (optional) */
size_t (*get_info)(struct sock *sk, u32 ext, int *attr,
union tcp_cc_info *info);
char name[TCP_CA_NAME_MAX];
struct module *owner;
};
用户可以通过自定义以上钩子函数实现定制拥塞控制算法,并进行注册。以下截取cubic拥塞控制算法对接口的实现、注册****的代码片段。 可以注意到cubic只实现了拥塞控制引擎tcp_congestion_ops的部分钩子函数,因为有一些钩子函数是必须实现,有一些是根据算法选择实现的。
static struct tcp_congestion_ops cubictcp __read_mostly = {
.init = bictcp_init,
.ssthresh = bictcp_recalc_ssthresh,
.cong_avoid = bictcp_cong_avoid,
.set_state = bictcp_state,
.undo_cwnd = tcp_reno_undo_cwnd,
.cwnd_event = bictcp_cwnd_event,
.pkts_acked = bictcp_acked,
.owner = THIS_MODULE,
.name = "cubic",
};
static int __init cubictcp_register(void)
{
BUILD_BUG_ON(sizeof(struct bictcp) > ICSK_CA_PRIV_SIZE);
beta_scale = 8*(BICTCP_BETA_SCALE+beta) / 3
/ (BICTCP_BETA_SCALE - beta);
cube_rtt_scale = (bic_scale * 10); /* 1024*c/rtt */
cube_factor = 1ull < < (10+3*BICTCP_HZ); /* 2^40 */
/* divide by bic_scale and by constant Srtt (100ms) */
do_div(cube_factor, bic_scale * 10);
return tcp_register_congestion_control(&cubictcp);
}
static void __exit cubictcp_unregister(void)
{
tcp_unregister_congestion_control(&cubictcp);
}
module_init(cubictcp_register);
module_exit(cubictcp_unregister);
在Linux用户态可以 通过参数查看当前使用的拥塞控制算法、当前可支持的拥塞控制算法 。如下表所示是两个参数以及含义。
| 参数 | 含义 |
|---|---|
| net.ipv4.tcp_congestion_control | 当前运行的拥塞控制算法 |
| net.ipv4.tcp_available_congestion_control | 当前可支持的拥塞控制算法 |
具体如下图所示,通过参数看到当前可支持的拥塞控制算法以及当前使用的拥塞控制算法。可以看到当前可支持的拥塞控制算法中包含bbr算法, bbr算法在内核版本4.9开始支持的。

如果留意的话,在本文开始时提到了很多传统的拥塞控制算法,那么在上面的命令中没有看到,其实有众多拥塞控制算法在Linux中没有进行安装,如下命令 查看Linux系统中所有已实现的拥塞控制算法模块 :
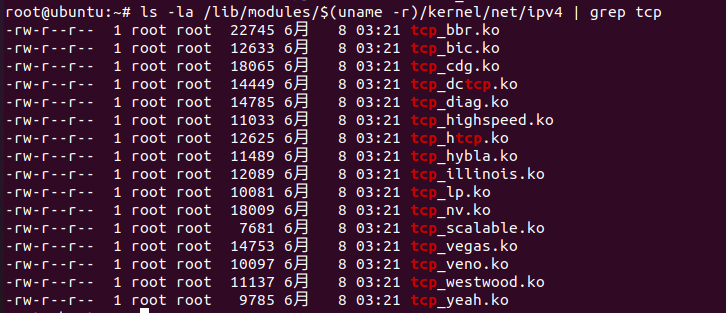
如果想安装特定的拥塞控制算法可以通过modprobe命令对指定的拥塞控制算法进行安装,如下所示安装了Vegas拥塞控制算法,此时再查看当前系统中可以使用的拥塞控制算法,多了一个Vegas算法。

除了可以动态查看当前Linux系统可用的拥塞控制算法、当前使用的拥塞控制算法外还可以动态切换拥塞控制算法。如下所示将默认的cubic拥塞控制算法切换为bbr拥塞控制算法。

切换后验证如下,当前运行的拥塞控制算法由之前的cubic拥塞控制算法切换到了bbr拥塞控制算法。

至此本文关于Linux内核网络中拥塞控制的大概框架、原理介绍到这,文中有表达有误或者不准确的地方欢迎指正。关于具体的每个拥塞控制算法的实现,将在后续文章中呈现。
全部0条评论

快来发表一下你的评论吧 !

