

嵌入式技术
在Linux网络编程中,我们应该见过很多网络框架或者server,有多进程的处理方式,也有多线程处理方式,孰好孰坏并没有可比性,首先选择多进程还是多线程我们需要考虑业务场景,其次结合当前部署环境,是云原生还是传统的IDC等,最后考虑可维护性,其具体的对比在第三部分具体会展开说。
#include < unistd.h >
pid_t fork(void);
// 返回值:子进程返回0,父进程返回子进程的pid,出错返回-1。
上面是一个创建进程的函数,那执行当前函数内核会做哪些事情呢?
(1)如果需要创建进程需要调用fork,进程调用fork,当控制转移到内核中的fork代码;
(2)内核做分配新的内存块和内核数据给子进程;
(3)内核将父进程部分数据结构内容拷贝进子进程,有一部分使用写时复制(copy on write)和父进程共享;
(4)添加子进程到系统进程列表中,同时父进程打开的文件描述符默认在子进程也会打开,且描述符引用计数加1;
(5)fork返回,内核调度器开始调度,因此fork之后,变成两个执行流;
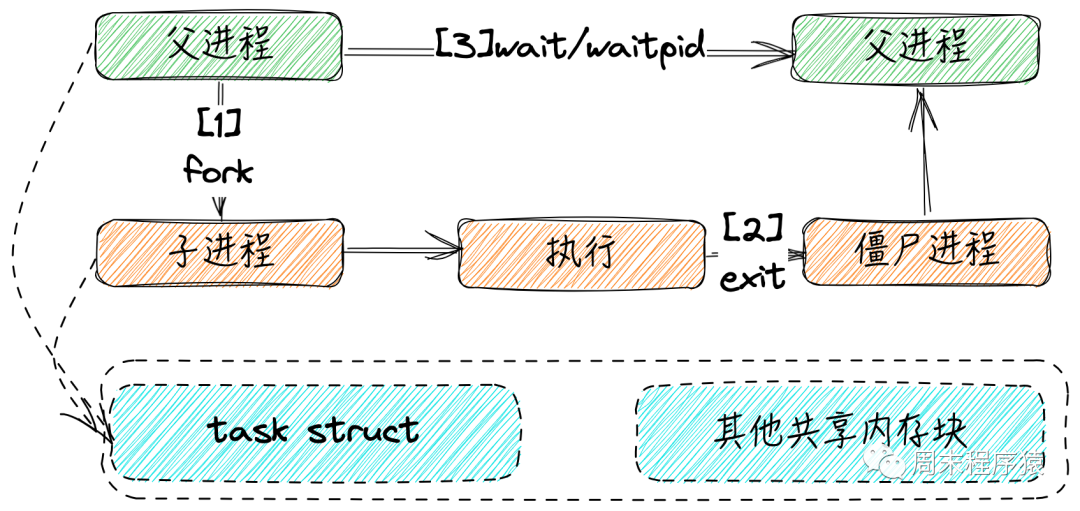
进程创建子进程,当子进程结束以后会出现两种情况。
(1)如果父进程还在,子进程退出到父进程读取状态之前,这段时间为僵尸态,之后父进程可以调用以下函数等待:
#include < sys/types.h >
#include < sys/wait.h >
pid_t wait(int *stat_loc);
pid_t waitpid(pid_t pid, int *stat_loc, int options);
// 代码样例
...
pid_t pid;
int stat;
while ((pid = waitpid(-1, &stat, WNOHANG)) > 0) { // 非阻塞等待
...
}
...
(2)如果父进程不在,此时子进程会被init进程接管,并等待结束,如果此时子进程一直不退出,就会一直占用内核资源;
在多进程编程模式中,各个进程不是孤立的,需要处理进程间通讯(IPC),如果您已经有所了解可以一起温故。
(1)管道
管道通讯方式在前面已经讲过,通过pipe系统函数创建fd[0]和fd[1],其中两个句柄就可以提供给父进程和子进程写入或者读出数据。
(2)信号量
信号量是为了解决访问临界区提供的一种特殊变量,支持两种操作:等待和信号,也就是对应P(进入临界区),V(退出临界区);
假设现在有信号量SV,其执行:
SV > 0,SV将减1;如果SV == 0,挂起的当前进程;Linux系统API如下:
#include < sys/sem.h >
int semget(key_t key, int nums, int sem_flags);
int semop(int sem_id, struct sembuf *sem_ops, size_t num_sem_ops);
int semctl(int sem_id, int sem_num, int command, ...);
semget创建信号量,semop操作信号量,对应PV操作,semctl允许对信号量直接控制,为了方便大家理解,在此给一段代码。
...
// op == -1:执行P操作,op == 1:执行V操作
void pv(int sem_id, int op) {
struct sembuf sem;
sem.sem_num = 0;
sem.sem_op = op;
sem,sem_flg = SEM_UNDO;
semop(sem_id, &sem, 1);
}
int main(...) {
int sem_id = semget(IPC_PRIVATE, 1, 0666);
...
pid_t pid = fork();
if (id == 0) {
...
pv(sem_id, -1); // 执行P操作
...
pv(sem_id, 1); // 执行V操作
...
} else {
...
pv(sem_id, -1);
...
pv(sem_id, 1);
...
}
}
(3)共享内存
共享内存是在有些场景下,父进程和子进程需要读写大块的数据,因此Linux系统提供了shmget,shmat,shmdt,shmctl四个系统调用。
#include < sys/shm.h >
int shmget(key_t key, size_t size, int shmflg);
void* shmat(int shm_id, const void *shm_addr, int shmflg);
int shmdt(const void* shm_addr);
int shmctl(int shm_id, int command, struct shmid_ds* buf);
int shm_open(const char * name, int oflag, mode_t mode);
int shm_unlink(const char * name);
shmget创建共享内存或者获取已存在的共享内存,key标识全局唯一共享内存,size为设置共享内存大小,shmflg设置的一些宏;shmat共享内存被创建以后,不能直接访问,需要关联到进程的地址空间中,可以设置shm_addr = NULL由操作系统选择;shm_open和open调用类似,是POSIX方法,创建一个共享内存对象,返回句柄与mmap调用;shm_unlink删除共享内存标记;
为了方便大家理解,在此给一段代码:
...
shmfd = shm_open("xxxx", O_CREAT | O_RDWR, 0666);
share_mem = (char *)mmap(NULL, BUFFER_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shmfd, 0);
...
注意 :共享内存需要考虑多写多读的问题,如果多个进程写,需要加锁处理。
(4)消息队列
#include < sys/msg.h >
int msgget(key_t key, int msgflg);
int msgsnd(int msgid, const void * msg_ptr, size_t msg_size, int msgflg);
int msgrcv(int msgid, void * msg_ptr, size_t msg_sz, long int msgtype, int msgflg);
int msgctl(int msgid, int command, struct msgid_ds * buf);
msgget创建消息队列,key标识全局唯一,msgflg和其他IPC的参数类似;msgsnd和msgrcv是发送和写入消息类型的数据;
为了方便大家理解,在此给一段代码:
...
struct msg_buf
{
long int msg_type;
char text[BUFSIZ];
};
int main(int argc, char **argv)
{
int msgid = -1;
struct msg_buf data;
long int msgtype = 0;
// 建立消息队列
msgid = msgget((key_t)1234, 0666 | IPC_CREAT);
...
// 从队列中获取消息
while (1)
{
if (msgrcv(msgid, (void *)&data, BUFSIZ, msgtype, 0) == -1)
{
// ...
}
// 遇到end结束
if (strncmp(data.text, "end", 3) == 0)
{
break;
}
}
// 删除消息队列
if (msgctl(msgid, IPC_RMID, 0) == -1)
{
...
}
...
}
(5)UNIX域
除了以上的通用的IPC,socket的UNIX域也可以作为进程间通讯,比如使用socket(AF_UNIX, SOCK_STREAM, 0),或socketpair系统调用,或父进程创建一个127.0.0.1环回接口socket server,子进程通过socket client访问。
在多进程的网络编程中,实现方式有很多,但是总体还是围绕两条线,其一如何将新建连接分发给子进程,其二如何将数据/信号传给子进程,并监控子进程,下图是其实现方式之一(由于实现细节很多,后续会将实现代码开源到github):
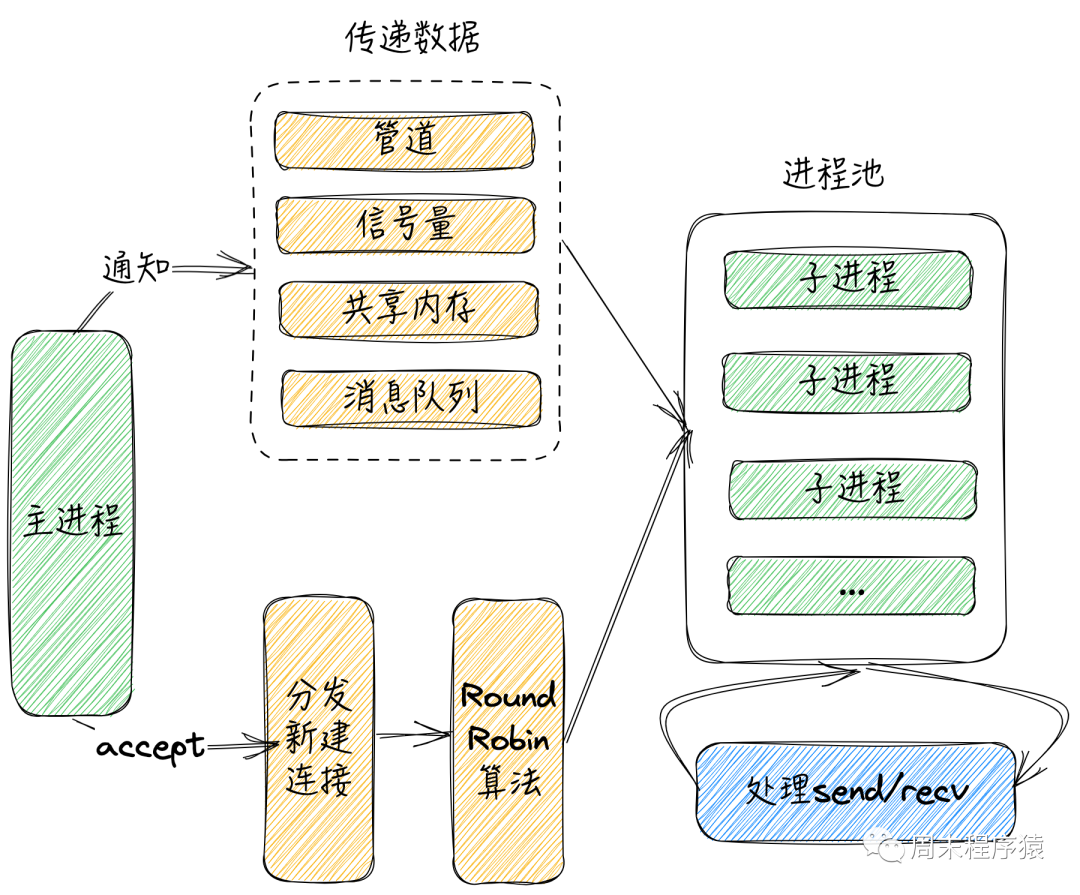
多进程
(1)首先为了性能考虑,进程池是必须的,通过线程池不需要频繁创建和销毁进程;
(2)其次主进程accept对应的新连接,考虑各个进程之间负载均衡,将新连接通过随机算法分发给子进程;
(3)分发方式可以通过管道,共享内存,消息队列等方式告知子进程,也可以传递数据信息;
(4)子进程收到新连接的句柄,就可以通过内部的epoll监听IO事件,从而完成send和recv;
在Linux中,线程是轻量级进程,运行在内核空间,由内核调度,最开始的线程库是linuxThreads,但是linuxThreads不符合POSIX标准,后来出现了NGPT和NPTL,其采用的线程模型不一样,所以性能有差异,性能由快到慢是:NPTL > NGPT > linuxThreads。
其中线程的模型分为三种:
linuxThreads和NPTL;现在Linux的2.6内核版本开始,默认使用NPTL线程库(1:1的线程模型),对比linuxThreads有如下优势:
#include < pthread.h >
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
void pthread_exit(void *retval);
int pthread_join(pthread_t thread, void **retval);
int pthread_cancel(pthread_t thread);
int pthread_detach(pthread_t thread);
pthread_t pthread_self();
(1)pthread_create创建线程,thread表示线程ID,attr表示设置线程属性,另外传递线程处理函数start_routine和参数arg;
(2)pthread_exit线程退出,可以在start_routine执行完成以后调用;
(3)pthread_join是等待线程结束,调用成功返回0,否则返回错误;
(4)pthread_cancel异常终止一个线程;
(5)pthread_detach把指定的线程转变为脱离状态,线程有两种属性,一种是joinable,一种是detached,当一个joinable线程终止时,它的线程ID和退出状态将留存到另一个线程对它调用pthread_join,调用前线程的资源不会释放,而脱离detached线程终止时,资源会立刻释放;
(6)pthread_self获取当前线程ID;
为了方便大家理解,在此给一段代码(使用c++11语法,底层是以上API的封装):
#include< iostream >
#include< pthread.h >
#include< thread >
void func(void *arg)
{
std::cout < < "threadid: " < < pthread_self() < < ", arg: " < < *(int*)arg < < std::endl;
}
int main()
{
int i = 1;
std::thread t1(func, &i);
t1.join();
++i;
std::thread t2(func, &i);
t2.join();
}
(1)信号量
#include < semaphore.h >
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destory(sem_t *sem);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
这里的API和多进程的信号量类似,就不展开详细说了,其中PV操作对应的函数是sem_wait信号量减1,sem_post信号量加1;
(2)互斥锁
互斥锁是线程独占临界区的控制方式,通过以下系统API:
#include < pthread.h >
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr);
int pthread_mutex_destory(pthread_mutex_t *mutex);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
pthread_mutex_init是锁mutex的初始化,mutexattr为设置锁属性,主要是类型:
PTHREAD_MUTEX_NORMAL普通锁,只能在同一个线程加锁解锁,但是加锁不可重入,其他线程不能解锁当前线程的锁,否则会导致死锁或者不可预期效果;PTHREAD_MUTEX_ERRORCHECK纠错锁,主要提供错误检查;PTHREAD_MUTEX_RECURSIVE嵌套锁,允许同一个线程重入加锁,不过其他线程需要这个锁,当前锁的拥有者需要执行相应次数的解锁,对已经被其他线程加锁的嵌套锁解锁或者对已经解锁的嵌套锁再解锁,都会返回错误;PTHREAD_MUTEX_DEFAULT默认锁,多次加锁解锁等行为是未定义;pthread_mutex_lock与pthread_mutex_unlock成对出现,这里要注意的是对于非嵌套锁,一定要注意死锁场景,另外不要对pthread_mutex_destory执行后的锁再执行加锁或者解锁操作;
(3)条件变量
条件变量是一种线程间通讯机制,当某个共享数据达到某个值得时候,唤醒等待该数据的线程继续执行,其API如下:
#include < pthread.h >
int pthread_cond_init(pthread_cont_t *cond, const pthread_contattr_t* cond_attr);
int pthread_cond_destory(pthread_cont_t *cond);
int pthread_cond_broadcast(pthread_cont_t *cond);
int pthread_cond_signal(pthread_cont_t *cond);
int pthread_cond_wait(pthread_cont_t *cond, pthread_mutex_t* mutex);
pthread_cond_init初始化条件变量cond,pthread_cond_destory销毁条件变量和释放占用内核资源,pthread_cond_broadcast广播唤醒所有等待cond的线程;pthread_cond_signal唤醒一个等待cond的线程,至于哪个被唤醒,取决于线程优先级和调度策略;
其中以上两个等待的函数是pthread_cond_wait,可能大家有点奇怪,为啥pthread_cond_wait需要带一个锁呢?这是mutex确保pthread_cond_wait操作的原子性,调用pthread_cond_wait之前需要将mutex加锁,pthread_cond_wait执行时候,首先会把调用线程放入条件变量的等待队列中,然后将mutex解锁,等pthread_cond_wait返回成功后,对mutex继续加锁,后续处理交给各自线程;
与多进程对比,多线程的处理方式相对就简单很多,由于在多线程内部数据是共享的,所以没有繁琐的数据传递,只需要队列就可以完成主线程和子线程之间的数据通信,下图是其实现方式之一(由于实现细节很多,后续会将实现代码开源到github):
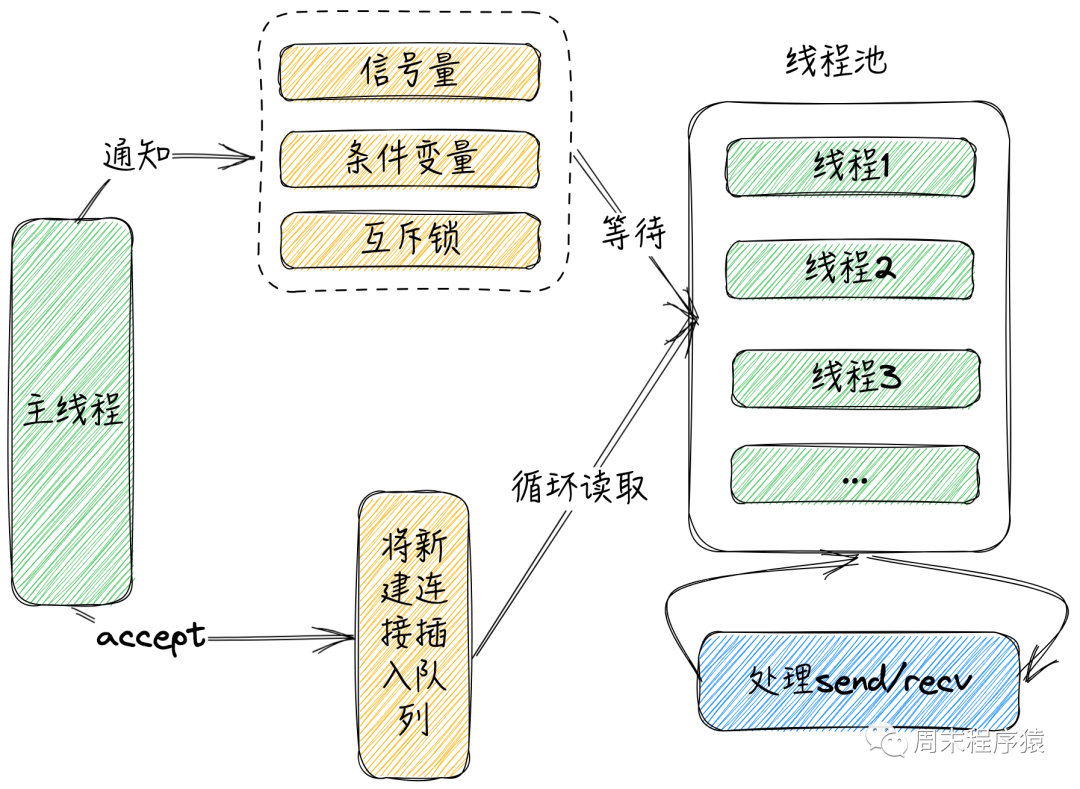
多线程
(1)和进程一样,为了性能考虑,线程池是必须的,这样对于IO密集型场景,处理线程一般是跑不满的;
(2)主线程accept对应的新连接,将新连接插入queue,同时通过信号量或条件变量或互斥锁告知线程池中的线程;
(3)线程池的线程收到通知,先开始抢锁,然后从队列中取出新连接;
(4)子线程拿到新连接的句柄,就可以通过内部的epoll监听IO事件,从而完成send和recv;
在云原生时代之前,多进程和多线程的网络框架的争论已久,每个开发者选择都有自己的考虑,比如多进程代表的web server是Nginx,Apache等,多线程的有Varnish,gRPC,libevent库等等,到底该如何选择网络框架呢?
(1)首先结合最大化利用多个处理器的硬件结构和软件架构,在大多数情况下,选择多线程或多进程处理,又或者两者兼用都能实现,但是这个选择将影响软件的性能、后期的维护、可扩展性、内存等各方面,所以开发网络框架之前一定要综合考虑;
(2)考虑多线程的优缺点:
(3)考虑多进程的优缺点:
以上的考虑是基于云原生时代之前,随着容器化的到来,我们应遵循"每个容器一个应用程序"的原则,原因如下:
实际选择和开发过程中,希望开发者更多结合业务场景来选择和设计网络框架。
全部0条评论

快来发表一下你的评论吧 !

