

电子说
CVPR 2023 中的领域适应:用于切片方向连续的无监督跨模态医学图像分割
前言
我们已经介绍过 3 篇 CVPR 中的典型领域适应工作,他们三篇都是 TTA(Test-Time Adaptation)的 settings,而这次要介绍的文章是 UDA(Unsupervised domain adaptation)的 setting。之前的三篇文章分别是:
CoTTA
EcoTTA
DIGA
在这篇文章中,提出了 SDC-UDA,一种简单而有效的用于连续切片方向的跨模态医学图像分割的体积型 UDA 框架,它结合了切片内和切片间自注意力图像转换、不确定性约束的伪标签优化和体积型自训练。与以前的医学图像分割 UDA 方法不同之处在于它可以获得切片方向上的连续分割(这一点有点重要,因为往往临床上都是一个 3D 数据,而直接处理 3D 数据又需要很大的计算资源),从而确保更高的准确性和临床实践中的潜力。
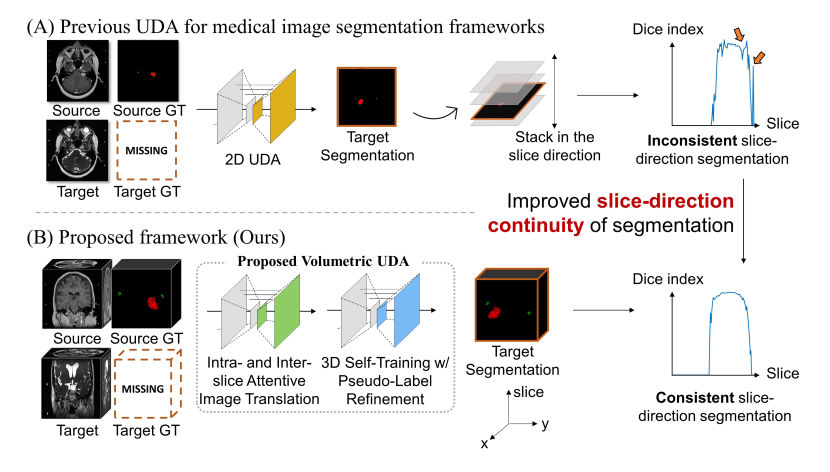
如上图所示,以前的医学图像分割 UDA 方法大多采用 2D UDA,当将预测堆叠在一起时,会导致切片方向上的预测不一致。SDC-UDA 在翻译和分割过程中考虑了体积信息,从而改善了分割结果在切片方向上的连续性,可以看到在图的最右侧,下面方法的 Dice 值在切片方向上是稳定的。
此外,我们全文中提到的“体积”这个词,可以理解为 3D 数据。
体积型 UDA 框架概述
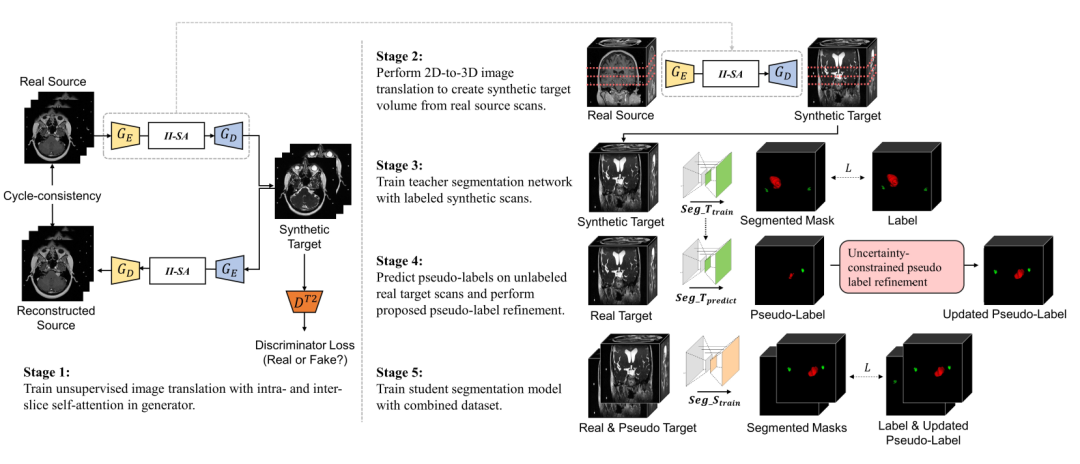
如下图所示,SDC-UDA 大致有五个步骤,从 stage 1 到 stage 5:
stage 1:带有片内和片间注意力的对抗学习过程,这一步是 stage 2 的基础,stage 2 是该步骤的上半部分。后面会单独用一个小节介绍。
stage 2:target 模态数据生成,假如 source 数据模态是 MRI,那么在这个步骤我们会得到 3D 的 CT 和对应的 label。
stage 3:把生成的 target 数据和 label 送入到教师网络训练。
stage 4:将真实的不带标签的 target 数据输入到 stage 3 的教师网络得到伪标签,并通过不确定性抑制优化伪标签。
stage 5:将生成的 target 数据、真实 target 数据和他们的标签用于优化学生网络,最终的预测也是在学生网络上。
请添加图片描述
具体实现
Unpaired 图像转换
先前的 2D UDA 方法将 3D 体积分割成 2D 切片,并在之后将它们的转换重新堆叠成 3D 体积。由于切片是单独处理的,重新构建转换后的体积通常需要额外的后处理,如切片方向插值,但这仍然无法完全解决切片方向不连续等问题。为了解决 2D 方法缺乏对体积性质的考虑和 3D 方法的优化效率问题,这篇文章提出了一种简单而有效的像素级领域转换方法,用于医学图像体积数据,通过使用切片内部和切片间自注意力模块将一组源域图像转换为目标域图像。与先前的 2D 方法只在单个切片内进行转换,而这篇文章的方法利用了切片方向上相邻切片的信息。这类似于最近在视频处理中的进展,它利用了帧内部和帧之间的信息。与需要昂贵计算成本的 3D 方法相比,不需要大量计算(下采样)。
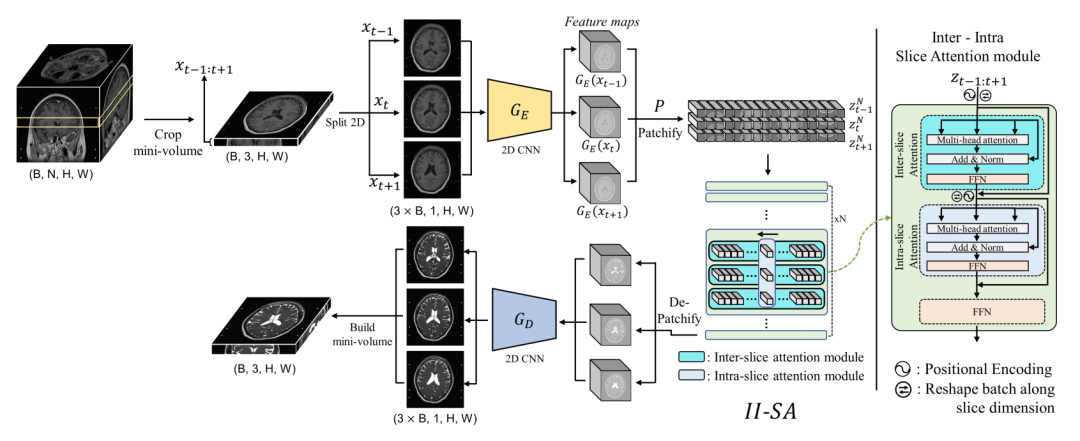
如上图所示,首先我们将一个 3D MRI 数据裁剪出 3 张切片,输入到 CNN 的 encoder中,encoder 的输出是三张切片的 feature maps,即在通道维度上被卷积。然后我们在长和宽的方向上裁剪 patches,这样会得到若干个 patch 块,输入到带有片内和片间的切片注意力模块中。这个注意力模块就是很普通的多头注意力、残差和 FFN 的两次组合。最后我们做相反过程的 decoder,这时生成的图像应该是 target 模态的。为了方便理解,可以再去看看我们在上一节提到的 stage 1,对应 stage 1 的上半部分。
stage 1 除了包括上面提到的这个过程,还包括重建的反过程(下半部分),这样我们才能计算一致性的 loss,同时利用对抗学习的判别器,完成自监督的训练。
体积自训练和伪标签优化
我们已经介绍了概述中第一个 stage,这一节对应后面三个 stage。
通过从源域转换的合成数据 x˜t 和注释 ys(即带标签的合成数据集),我们首先训练一个教师分割网络 teacher,该网络最小化分割损失:
训练完教师模型,可以通过将真实的目标域数据 xt 传递给训练好的分割模型 teacher,获取未标记真实数据的伪标签 y˜t。
由于 teacher 预测出的伪标签是噪声标签,必须对其进行改进,以提高准确性并引导自训练朝更好的方向发展。这篇文章设计了一种增强敏感性(SE)和特异性(SP)的伪标签改进模块,该模块基于图像强度、当前伪标签和不确定性区域(高于阈值)来改进伪标签。
通过预测出的伪标签,计算与每个类别相对应的不确定性(即熵)图:
其中 p 是每个类别的输出概率图。为了增强伪标签的敏感性,检测超出伪标签范围的高度不确定的区域。然后,如果该区域中的像素强度在当前伪标签包含的图像强度的某个范围内,该区域将被包括为伪标签的一部分。该公式可以表示为:
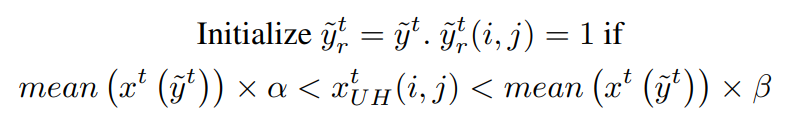
其中 分别表示目标域图像、伪标签、改进的伪标签和裁剪了高不确定性区域掩码。该方法基于假设:在医学图像中,具有相似强度且相互接近的像素很可能属于同一类别。
为了增强伪标签的特异性,也是检测伪标签范围内的高度不确定的区域。区别是,如果该区域中的像素强度不在当前伪标签包含的图像强度的某个范围内,则将其从当前伪标签中排除。可以表示为:
上面这个流程,文章中给出了图示如下,有助于理解这个流程:
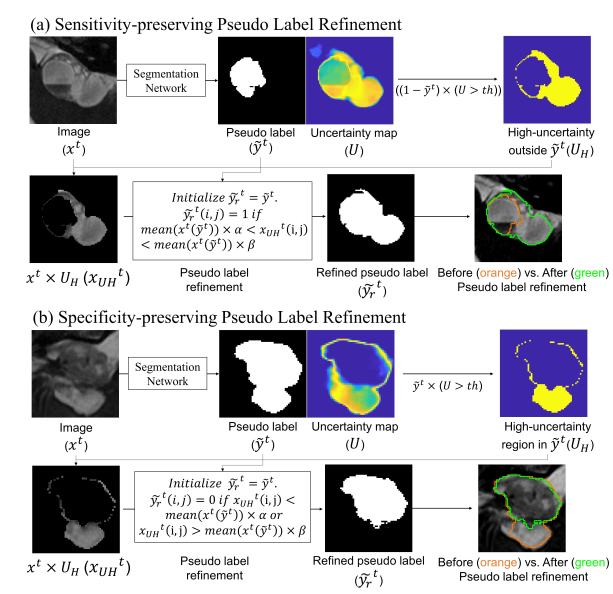
请添加图片描述
在 stage 5 中,合成的 target scans 与真实 target scans 存在分布差异。这篇文章将这两种配对数据结合到自训练中,以最大程度地提高泛化能力,并最小化由于分布差异而引起的性能下降。把带标签的合成 target scans 和带伪标签的 target scans 的数据合并,训练一个学生分割模型 student,以最小化以下损失:
实验
下表是 SDC-UDA 与以前的非医学图像和医学图像 UDA 方法之间的定量结果的比较。该表包括非医学图像 UDA 方法(例如 cycleGan、cycada、ADVENT 和 FDA)的结果,以及最近的医学图像 UDA 方法(例如 SIFA 和 PSIGAN)的结果。对比发表在 TMI 2020 上的 PSIGAN 方法,DICE 指标上提升了很多,特别是从 T1 到 T2 的跨模态设置。MRI 到 CT 也有显著的提升。
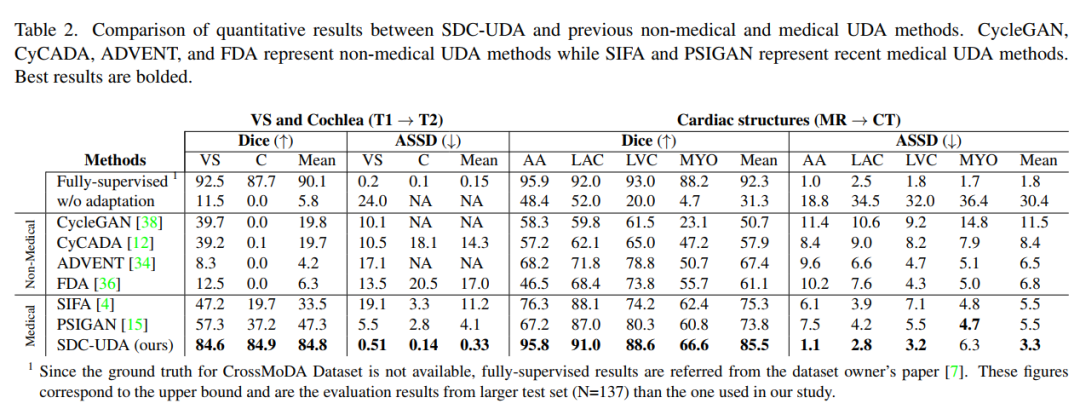
请添加图片描述
可视化结果比较如下图:
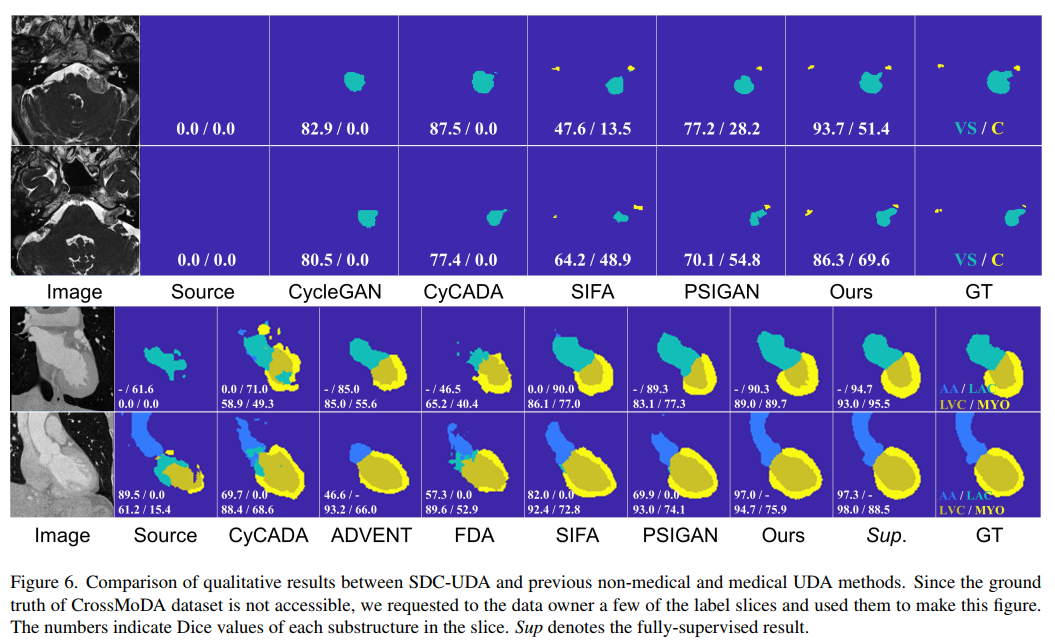
请添加图片描述
总结
这篇文章提出了 SDC-UDA,一种用于切片方向连续的跨模态医学图像分割的新型 UDA 框架。SDC-UDA 通过切片内部和切片间的自注意力有效地转换医学体积,并通过利用不确定性图,设计简单而有效的伪标签细化策略。通过体积级自训练更好地适应目标域。
现在的 SDC-UDA 框架中,只有 stage 1 是不需要训练 3D 图像的,后面的过程仍然是 3D 的训练(可能出于准确率的角度),也需要消耗更多的计算资源,其实也是可以优化成一组堆叠切片的。
参考
https://arxiv.org/pdf/2305.11012.pdf
全部0条评论

快来发表一下你的评论吧 !

