

作者:泡椒味的口香糖
0. 笔者个人体会
相似结构一直是SLAM和SfM中很难处理却又不得不处理的问题,如果机器人遇到了非常相似但实际不同的结构,很容易因为匹配数量足够多而引发假阳性回环和重建失败。传统方法更多的还是利用匹配数量的阈值或者和其他几何关系的比值阈值来判断,这种方法在遇到高对称结构时很容易失败。
今天笔者将为大家带来这个问题新的解决思路,也就是ICCV 2023 Oral提出的Doppelgangers,能够自动判断两个视图是相同的,还是仅仅是相似的。这个方案实际上是将视觉消歧问题建模为图像对上的二分类任务,并开发了基于学习的解决方案和数据集。
1. 效果展示
以下是一些典型的相似结构,即便是使用人眼观看,也很容易认为是相同场景。而在SLAM和SfM遇到这类场景时,很容易触发假阳性回环而导致跟踪丢失或重建失败。
Doppelgangers这篇文章主要解决的就是这类场景下的匹配和重建问题,即便用来重建的场景具有高度对称和相似的结构,仍然可以进行完整的三维重建,不会凭空多或者少一些结构。


2. 摘要
我们考虑视觉消歧任务,即判断一对视觉相似的图像是否描绘了相同或不同的三维表面(例如,对称建筑物的同侧或对侧)。虚假图像匹配,即两幅图像观察到不同但视觉上相似的3D表面,对人类区分具有挑战性,也会导致3D重建算法产生错误的结果。我们提出了一种基于学习的视觉消歧方法,将其建模为图像对上的二分类任务。为此,我们为该问题引入了一个新的数据集Doppelgangers,该数据集包含了具有真实标签的相似结构的图像对。我们还设计了一种网络架构,将局部关键点和匹配的空间分布作为输入,从而可以更好地对局部和全局线索进行推理。我们的评估表明,我们的方法可以在困难的情况下区分误匹配,并且可以集成到SfM流水线中,以产生正确的、无二义性的三维重建。
3. 算法解析
现在一步步来拆解任务:我们希望在做SLAM和SfM时,即便遇到了结构非常相似的场景,也能够正确进行三维重建和跟踪,不能出现误匹配导致重建结果突然多了一块或少了一块,更不能出现假阳性回环。
具体任务描述:
给定两幅非常相似的图像,判断它们是同一个结构的同一个表面,还是两个不同的3D结构(作者将其称为doppelgangers)。主要发生在对称建筑物、重复视觉元素、以及多个相同地标场景中。
分析发现,虽然从高度对称建筑拍摄的两幅图像整体很相似,很难直接通过图像对来进行正负判别,但是它内部还是有一些细节是不同的。这些细节所在的区域在进行图像匹配时的匹配关系很少,利用这种细微差异就可以区分图像。其实这样很符合人类"找不同"的思路。
基于这个发现,作者就提出了一种基于学习的方法来消除视觉歧义,并且还公开了一个具有相似结构的数据集,数据集还有GT标签。
这个相似场景识别算法的原理是,首先使用RANSAC估计基础矩阵并过滤异常匹配(具体实验是直接使用LoFTR+RANSAC计算匹配),将原图、提取的特征点、匹配到的特征点输入到网络中,输出为相似图像的概率,将相似性识别转换为一个二分类问题。
这个算法的思想是使用关键点和匹配位置为网络提供信息,这样网络不仅知道哪些关键点被匹配了,也可以知道哪些关键点没有匹配,这样对应的区域可能就代表信息缺失或者不同目标,相当于利用了关键点和匹配的空间分布信息。很明显,视觉上具有相似结构区域的匹配会更稠密,但不同结构的区域匹配更稀疏。
而且为了更好得比较不同结构区域,作者还对输入图像对进行了几何对齐,也就是估计仿射变换,然后warp图像和二值mask。当然,这个对齐不一定特别准,只不过希望能够更好得联系将两个重叠区域。
到具体训练这一块,作者还使用了Focal loss。这个也很容易理解,相似结构的特征点匹配肯定是正负样本不平衡的,使用Focal loss可以提高难分样本的贡献。
4. 实验
用来做二分类的网络结构很简单,就是3个残差模块,一个平均池化,再加上一个全连接层。也仅仅训练了10个epoch,batch size设置为16,学习率从0.0005降低到0.000005。
实验主要是在他们提出的Doppelgangers数据集上评估消除视觉歧义的性能,然后将训练的图像二分类器集成到SfM中,通过重建效果来评估消歧性能,最后搞了一个消融实验来证明每个模块都是有用的。
首先是仅使用局部特征匹配来预测图像对是否为正(真)的匹配,对比的baseline包括SIFT+RANSAC、LoFTR、以及DINO-ViT(自监督SOTA分类/分割器)。作者使用的匹配方式包括两种:( 1 )对几何验证后的匹配数量进行阈值化处理;( 2 )对匹配数量与关键点数量的比值进行阈值化处理。( 2 )背后的思想是,如果相对于关键点的数量,有很少的匹配,则很可能是误匹配。作者训练的模型AP为95.2 %,ROC AUC为93.8 %。DINO结果不太好,主要是因为它生成的特征很适合语义分类任务,但不适合视觉消歧。
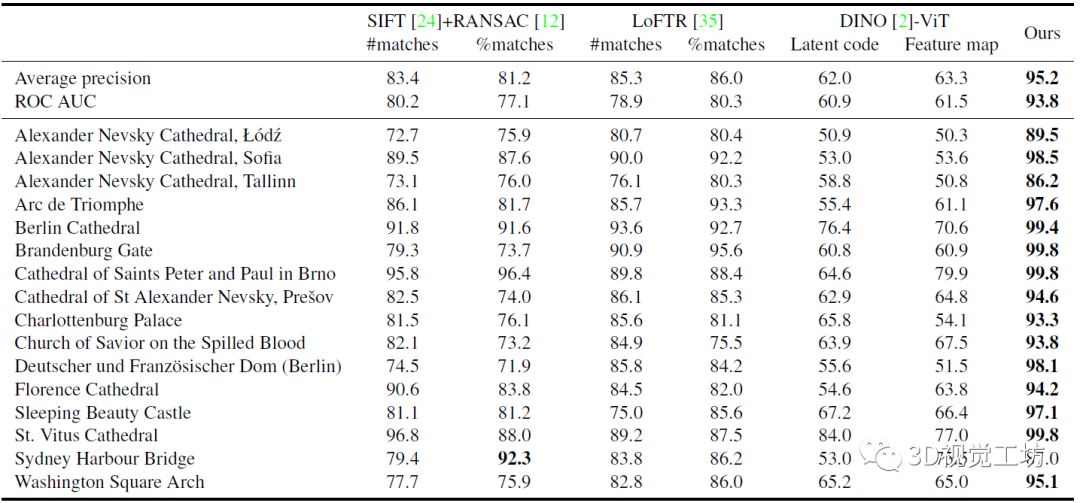
测试的图像对和对应的正匹配概率,这个定性对比还是很详细的,实验的场景很多。左栏表示负对匹配关系(错误),右栏表示正对(正确)。比较亮眼的是,在不同光照、视角变化、天气变化等挑战性情况下,也可正确分类正负匹配关系。
后面就开始搞三维重建了,作者将他们训练的二分类器集成到COLMAP中,以此来评估在重复/对称场景中的三维重建效果。使用的landmark有两类,包含13个由于对称和重复结构而难以重建的landmark,还有与训练数据有显著差异的3个具有重复结构的场景,主要是为了测试泛化性。
下面这个表就是SfM的重建结果,第二列代表数据集中的场景数量,其他的√和代表是否重建成功,是否成功是与谷歌地球中相应结构对比得到的(评估三维重建效果的新点?)。
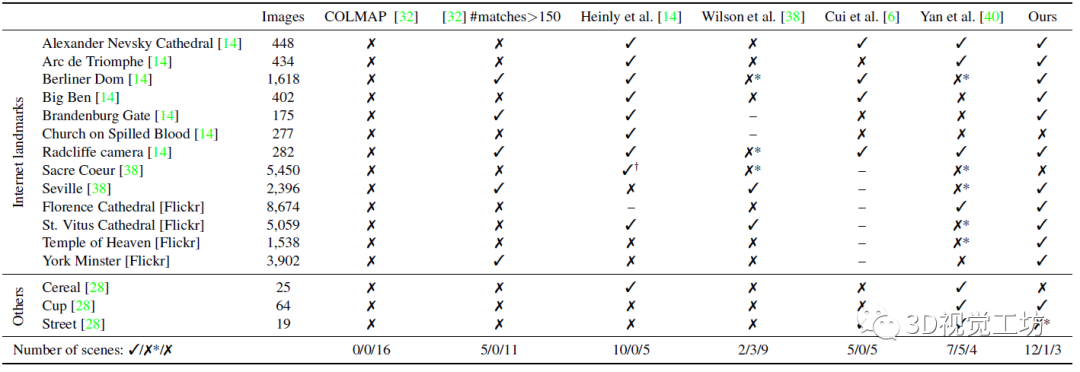
下面是直接使用COLMAP重建的模型和作者提出方法重建效果的对比。显然,直接使用COLMAP会凭空产生很多多余的塔楼、穹顶等结构。但是作者提出的方法可以很好得消除这种对称相似结构的"语义歧义",从而重建完整的三维模型。

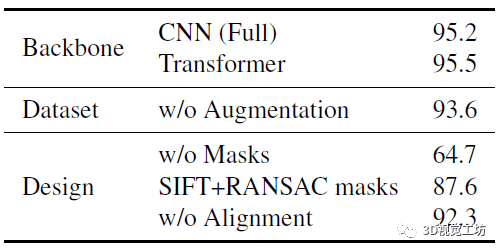
最后是一个消融实验,就没啥可说的了,主要对比了使用不同的网络结构做二分类器、书否有数据增强,以及不同网络输入带来的性能对比。
5. 总结
Doppelgangers是解决特定任务的一篇文章,实现了相似结构的二分类,解决的问题很重要。虽然Doppelgangers的实验更多的面向图像匹配和SfM,但笔者个人觉得也很容易应用到SLAM场景中,感兴趣的小伙伴可以做进一步的尝试。
编辑:黄飞
全部0条评论

快来发表一下你的评论吧 !

