

1►
ARM映像文件组成
ARM 映像文件其实就是源文件经编译器生成的目标文件,一般是bin文件或者hex文件,可以直接烧录到ROM中执行(一般是内部FLASH),这个文件称为可执行映像文件(image file)。
映像文件一般由域组成,域最多由三个输出段组成(RO,RW,ZI)组成,输出段又由输入段组成。所谓域,指的就是整个映像文件所处在的区域,它又分为加载域和运行域。我们输入的代码,一般有代码部分和数据部分,这就是所谓的输入段,经过编译后就变成了映像文件中的RO段和RW段,还有所谓的ZI段,这就是输出段。
加载域:映像文件被静态存放的工作区域。
运行域:程序运行起来的存储区域。
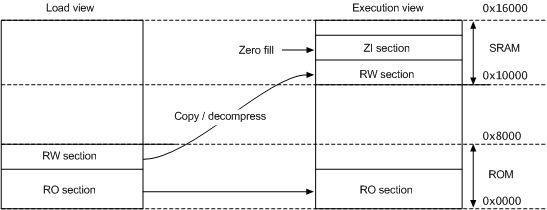
程序在存储状态时,RO段及RW段都被保存在ROM区。
当程序开始运行时,内核直接从 ROM 中读取代码,并且在执行主体代码前,会先执行一段加载代码,它把 RW 段数据从 ROM 复制到 RAM,并且在 RAM加入 ZI 段,ZI 段的数据都被初始化为 0。加载完后 RAM 区准备完毕,正式开始执行主体程序。
2►
分散加载机制
分散加载机制允许开发者为代码或数据变量在加载和执行时指定不同的存储空间,通知链接器把程序的某一部分链接在存储器的某个地址空间。
2.1 何时使用分散加载
实现嵌入式系统通常需要分散加载,这些系统使用ROM、RAM和内存映射的外设。通常需要分散加载的情况如下:
1)复杂内存映射:
必须放置在许多不同内存区域的代码和数据需要详细的指令来说明在内存空间中放置这些部分的位置。
2)不同类型的内存:
许多系统包含各种物理存储设备,如FLASH、ROM、SDRAM和快速SRAM。分散加载描述可以将代码和数据与最合适的内存类型相匹配。例如,中断代码可以放在快速的SRAM中以改善中断响应时间,但不常用的配置信息可以放在较慢的闪存中。
3)内存映射的外设:
分散加载描述可以将数据段放置在内存映射中的精确地址上,以便可以访问内存映射的外设。
4)函数在固定位置:
即使周围的应用程序已被修改和重新编译,也可以将函数放置在内存中的相同位置。这对于跳转表的实现很有用。
5)使用符号来标识堆和堆栈:
在链接应用程序时,可以为堆和堆栈位置定义符号。
2.2 怎么使用分散加载
1)对于具有简单内存映射(仅有SRAM和ROM)的image文件,可以仅使用链接器命令行选项或scatter文件来指定内存映射。下图显示了一个简单的内存映射:
2)对于具有复杂内存映射(具有DRAM、SRAM、ROM2、ROM1等)的image文件,不能仅使用链接器命令行选项指定内存映射,需要使用scatter文件。下图显示了一个复杂的内存映射:

3►
分散加载文件说明
分散加载文件(scatter file)是一个文本文件,它的作用是可以用于描述 ARM 链接器生成映像文件所需要的信息。如果不使用分散加载文件来指定,那么 ARM 链接器会按照默认的方式来生成映像文件。Keil的分散加载主要是通过 .sct 文件实现的,链接器根据 .sct 文件的配置分配各个段区地址,生成分散加载代码。
编写分散加载文件中可以指定下列信息:
1)各个加载域的加载起始地址、最大尺寸和属性。
2)各个加载域中包含的输出段。
3)各个运行域的运行起始地址、最大尺寸、存储访问特性和属性。
4)各个运行域中包含的输入段。
一个Scatter文件包含若干个加载域,一个加载域包含若干个输出段,一个输出段由若干个具有相同属性的输入段组成。
4►
分散加载文件语法
Scatter文件是一个文本文件,使用BNF语法来描述ARM链接器生成映像文件时所需要的信息。
BNF符号与语法:
" :由双引号标识的符号保持其字面原意,如A”+”B表示A+B。
A ::= B :定义A为B。
[A] :用来表示可选部分,如A[B]C表示ABC或AC。
A+ :用来表示A可以重复任意次,如A+表示A,AA,AAA,......
A* :同A+。
A | B :用来表示选择其一,不能全选。如A|B表示A或者B。
(AB) :表示一个整体,通常其他符号一起使用,如(AB)+(C|D)表示ABC,ABD,ABABC,ABABD,......
一个Scatter文件包含一个或多个加载区域,每个加载区域可以包含一个或多个执行区域。下图显示了典型的Scatter文件的组成结构:
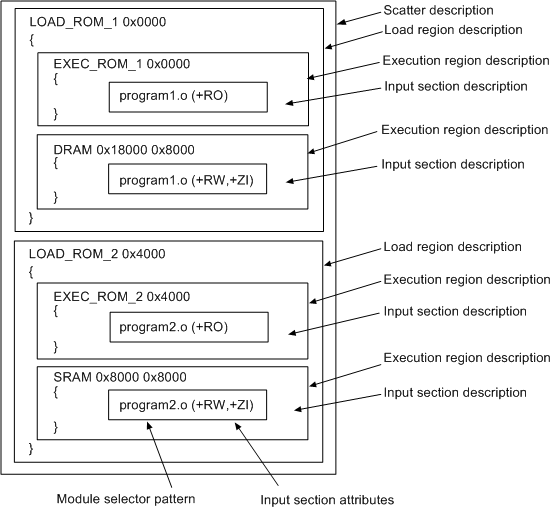
4.1 加载域描述
加载域可以包含一个或多个执行域。
加载域描述的语法如下:
load_region_description ::=
load_region_name (base_address | ("+" offset)) [attribute_list] [max_size]
"{"
execution_region_description+
"}"
1)load_region_name:命名加载区域。你可以使用带引号的名字。只有在使用任何与区域相关的链接器定义的符号时,该名称才区分大小写。
2)base_address:指定区域内对象的链接地址。base_address必须满足加载区域的对齐约束。
3)+offset:描述基址,该基址在前面的加载区域的末尾以外偏移字段。偏移量的值必须是0取4的模。如果这是第一个加载区域,那么+offset表示基址从零开始偏移字段。如果使用+offset,则加载区域可能会从前一个加载区域继承某些属性。
4)attribute_list:指定加载区域内容的属性。
5)max_size:指定加载区域的最大大小。这是在进行任何解压缩或零初始化之前加载区域的大小。如果指定了可选的max_size值,那么如果分配给该区域的字段超过max_size, armlink将生成一个错误。
6)execution_region_description:指定执行区域的名称、地址和内容。
4.2 执行域描述
执行域指定在运行时将输入段放置在目标内存中的位置。
执行域描述的语法如下:
execution_region_description ::=
exec_region_name (base_address | "+" offset) [attribute_list] [max_size | length]
"{"
input_section_description*
"}"
1)exec_region_name:命名执行区域。你可以使用带引号的名字。只有在使用任何与区域相关的链接器定义的符号时,该名称才区分大小写。
2)base_address:指定区域内对象的链接地址。Base_address必须与字对齐。
注意:在执行区域上使用ALIGN会导致加载地址和执行地址对齐。
+offset:描述一个基址,该基址在前面执行区域的末尾以外偏移字段。偏移量的值必须是0取4的模。如果这是加载区的第一个执行区,则+offset表示基址在包含加载区的基址之后开始偏移字段。如果使用+offset,则执行区域可能会从父加载区域继承某些属性,或者从同一加载区域内的前一个执行区域继承某些属性。
4)attribute_list:指定执行区域内容的属性。
5)max_size:对于标记为EMPTY或FILL的执行区域,max_size值被解释为该区域的长度。否则,max_size值将被解释为执行区域的最大大小。
6)-length:只能与EMPTY一起使用,表示在内存中增长的堆栈。如果长度为负值,则base_address被视为该区域的结束地址。
7)input_section_description:指定输入段的内容。
4.3 输入段描述
输入段描述指定将哪些输入段加载到执行区域。
输入段描述的语法是:
input_section_description ::=
module_select_pattern [ "(" input_section_selector ( "," input_section_selector )* ")" ]
input_section_selector ::= "+" input_section_attr
| input_section_pattern
| input_section_type
| input_symbol_pattern
| section_properties
1)module_select_pattern:
一种由文本构成的模式。当module_select_pattern匹配以下选项之一时,输入段匹配模块选择器模式:
包含该段的目标文件的名称。
库成员的名称(不带前导路径名)。
提取部分的库的全名(包括路径名)。如果名称包含空格,请使用通配符以简化搜索。
例如,使用*libname来匹配C:lib dirlibname.lib。
通配符 * 匹配零个或多个字符,? 匹配任意单个字符。匹配不区分大小写,即使在文件命名区分大小写的主机上也是如此。使用 *.o 匹配所有对象,使用 * 来匹配所有的目标文件和库。可以使用带引号的文件名,例如”file one.o”。
在一个Scatter文件中不能有两个 * 选择器。但是可以使用两个修改过的选择器,例如*A和*B,并且可以将. any选择器与*模块选择器一起使用。*模块选择器的优先级高于.any。如果文件中包含*选择器的部分被删除,则. any选择器将变为活动的。
2)input_section_attr:
与输入部分属性匹配的属性选择器。每个input_section_attr后面跟着一个+。选择器不区分大小写,可以识别以下选择器:
RO-CODE
RO-DATA
RO,同时选择RO-CODE和RO-DATA
RW-DATA
RW-CODE
RW,同时选择RW-CODE和RW-DATA
XO
ZI
ENTRY,包含入口点的部分。
可以识别以下同义词:
CODE代表RO-CODE
CONST代表RO-DATA
TEXT代表RO
DATA代表RW
BSS代表ZI
可以识别以下伪属性:
FIRST
LAST
如果放置顺序很重要,则使用FIRST和LAST标记执行区域中的第一部分和最后一部分。例如,如果特定的输入部分必须在区域中位于第一个,并且包含校验和的输入部分必须位于最后。
FIRST和LAST必须不违反基本属性排序顺序。例如,FIRST RW放在任何只读代码或只读数据之后。
一个执行区域只能有一个FIRST或一个LAST属性,并且它必须遵循一个input_section_selector。例如:
*(section, +FIRST) 这种模式是正确的。
*(+FIRST, section) 此模式不正确,并产生错误消息。
3)input_section_pattern:
一种模式,不区分大小写,与输入段名匹配。它是由文字构成的。通配符 * 匹配0个或多个字符,而 ? 匹配任何单个字符。可以使用带引号的输入段名。
如果使用多个input_section_pattern,请确保在不同的执行区域中没有重复的模式,以避免歧义错误。
4)input_section_type:
与输入段类型进行比较的数字。支持十进制或十六进制。
5)input_symbol_pattern:
可以通过该段定义的全局符号名选择输入段。全局名称能够使你从部分链接的对象中选择具有相同名称的单个段。
6)section_properties:
section属性可以是+FIRST、+LAST和OVERALIGN值。OVERALIGN的值必须是2的正幂,且必须大于或等于4。
5►
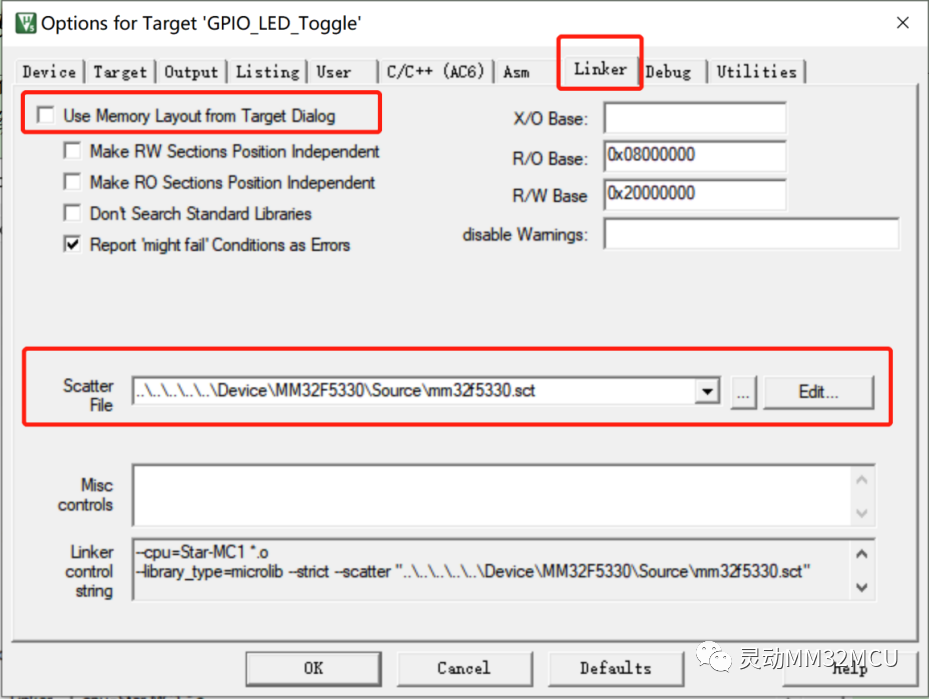
如何打开.sct文件
在Options for Targets->Linker界面,Keil默认选择了“Use Memory Layout from Target Dialog”,勾掉复选框里面的对号,就可以使用自己定义的分散加载文件。
6►
练习
根据前面介绍的语法编辑 .sct文件,将函数和数据放到指定地址:
1)在LR_ROM加载域中定义2个执行域RW_RAM1、RW_RAM2:
RW_RAM1基地址为0x20001000,域大小为0x400,将TEST_FUNCTION_ADDR段最先加载到本域的起始地址。
RW_RAM2基地址为0x20001400,域大小为0x400,将TEST_DATA_ADDR段最先加载到本域的起始地址。
LR_ROM __RO_BASE __RO_SIZE { ; load region size_region
ER_ROM __RO_BASE __RO_SIZE { ; load address = execution address
*.o (RESET, +First)
*(InRoot$$Sections)
; *(Veneer$$CMSE) ; uncomment for secure applications
.ANY (+RO)
.ANY (+XO)
}
RW_RAM __RW_BASE __RW_SIZE { ; RW data
.ANY (+RW +ZI)
}
RW_RAM1 0x20001000 0x400 { ; RW data
*.o (TEST_FUNCTION_ADDR, +First)
}
RW_RAM2 0x20001400 0x400 { ; RW data
*.o (TEST_DATA_ADDR, +First)
}
#if __HEAP_SIZE > 0
ARM_LIB_HEAP __HEAP_BASE EMPTY __HEAP_SIZE { ; Reserve empty region for heap
}
#endif
ARM_LIB_STACK __STACK_TOP EMPTY -__STACK_SIZE { ; Reserve empty region for stack
}
}
2)使用__attribute__((section("section_name"))) 定义函数和数据如下:
(表示将函数或数据放入指定名为"section_name"的段)
uint32_t test_data __attribute__((section("TEST_DATA_ADDR")));
void test_function(void) __attribute__((section("TEST_FUNCTION_ADDR")));
3)调用上述函数和数据:
int main(void)
{
test_function();
while (1)
{
test_data ++;
if(test_data >= 1000)
{
test_data = 0;
}
}
}
编译后查看map文件中内存映射部分:
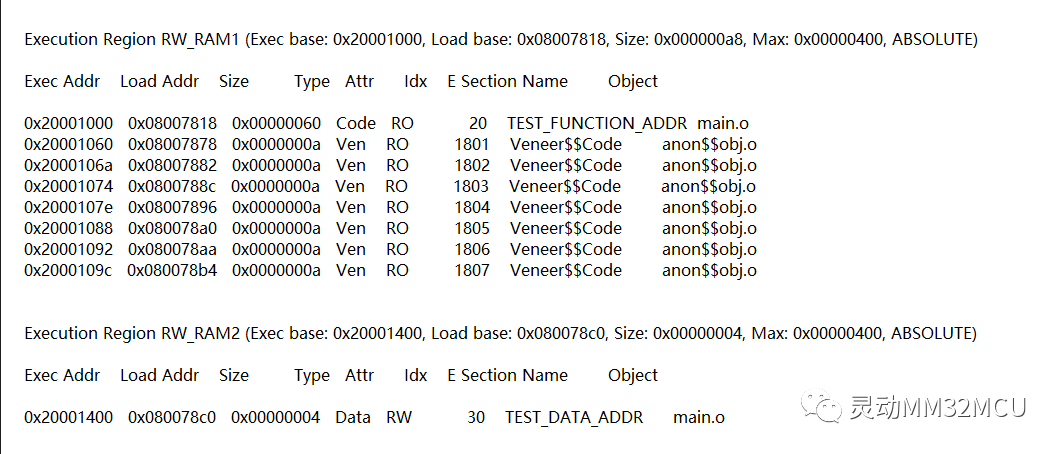
TEST_FUNCTION_ADDR段对应的执行域基地址为0x20001000,TEST_DATA_ADDR段对应的执行域基地址为0x20001400,和在Scatter文件定义一致,即将函数和数据放到了指定地址。
7►
小结
分散加载文件(scatter file)是一个文本文件,用于描述 ARM 链接器生成映像文件所需要的信息,在一些应用场景中嵌入式系统可能会使用分散加载。本章节简要介绍了分散加载文件的基本概念和语法,旨在对分散加载文件有初步认识,具体内容可以参考官方文档或查阅资料进行详细了解。
审核编辑:刘清
全部0条评论

快来发表一下你的评论吧 !

