

改变企业命运的前沿技术
本期Kiwi Talks 将讲述Chiplet技术是如何改变了一家企业的命运并逐步实现在高性能计算与数据中心领域的复兴。
当我们勇于承担可控的风险、积极寻求改变世界的前沿技术时,AMD 才会越来越好。
——AMD 董事会主席及首席执行官 Lisa Su 博士
开端:Why Chiplet?
2017年对于AMD公司来说是一个非常关键的转折点。在那之前的10年,AMD都面临着强劲的竞争对手,糟糕的财务负担。 那一年AMD实现了突破式的创新,以全新的Chiplet架构诞生 EPYC第一代处理器,标志着AMD在高性能计算领域的复兴,也是其在服务器市场上的重要里程碑。
回顾2017年,Global Foundries 从AMD剥离,这意味着公司从一家拥有晶圆厂的公司变成芯片设计公司。
在被问及是否因为晶圆协议才被迫选择Chiplet赛道时,首席执行官Lisa Su回应的答案:“完全不是,我们当时的想法是,我们需要为处理器市场带来一些与众不同的东西,因此制造这些良率不高、价格昂贵的巨型芯片并不是大家想要的答案。”

source:ieeetv
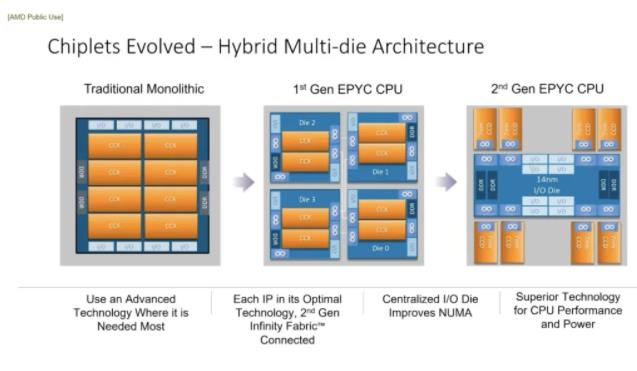
第一代EPYC Zen-1架构的服务器产品是由4个同样结构的Die(都含有计算核、DDR内存和I/O功能,I/O主要包括PCIe、以太网、CPU片间互连等)通过 IFOP(Infinity Fabric on Package,一种片内互连物理层技术)相连而成。 虽然当时AMD的Chiplet设计取得商业化成功,提升了CPU的市场份额,但Chiplet的技术发展一直面临着各种挑战。诚然,第一代产品整体的设计与制造降低了成本,采用的2D MCM设计改善了产品性能并增加了灵活性,然而增加芯片数目确会导致更大的片上系统(soc),由于组件之间的距离变大,导致了产品性能的延迟。
在7,8年前,要寻找到最合适的连接小芯片的封装技术也同样面临难题。这是一个复杂的等式,涉及成本、性能、带宽密度、功耗和制造能力。
在当时,大批量、低成本地生产它们和拥有封装工艺技术是两码事。为了坚持Chiplet的道路,AMD在制造工艺方面投入了大量的资金。
同年,NVIDIA创始人兼CEO黄仁勋在2017年Computex发布了 Tesla V100,号称是当年史上最强的GPU加速器。虽然 Tesla V100 在性能上极其优秀,但仍存在不少缺点。比如芯片面积过大——高达 815 平方毫米,而过大的芯片面积,加上英伟达在该款芯片上巨额的研发投入(约30亿美金)直接导致 Tesla V100 的价格异常昂贵,售价高达 14.9 万美元。如此高的售价让很多用户望而却步。 这也印证了随着芯片面积的增大,制造成本越发昂贵,后续行业纷纷为了实现降本都转向了Chiplet的设计架构。
进阶:I/O Die 架构的诞生
Central I/O Die 的架构,成功地提高处理器性能的同时,也提供了更高的能效比和更好的成本效益。
2018年AMD发布了下一代Zen 2 EPYC CPU。Zen 2架构的EPYC Rome 包括8个CCD(Core Chiplet Die)和1个IOD(I/O Die),CCD中包括CPU核心、缓存,后者包括各类控制器和输入输出处理器使,通过Infinity Fabric技术实现Chiplet之间的高速连接,从而构建出具有大量核心的高性能处理器。这种设计允许每个核心芯片拥有独立的L3缓存,并且可以独立地进行性能扩展和优化。
source:ieeetv
AMD后续推出的Zen3和Zen 4 EPYC CPU均沿用了I/O Die 的架构,成功地在提高处理器性能的同时,也提供了更高的能效比和更好的成本效益。

AMD的Zen3/ Zen4架构CPU,采用CCD(compute)和CIOD(memory interface + I/O)组合的形式进行不同Chiplets功能拆解。AMD Zen 4 EPYC 采用12个CDD+1个IO Die的方式,每个CDD包含12个核心,从而让其达到了96核心的设计。
目前,IO Die架构逐步成为Chiplet主流的一种形态被应用。例如Huawei Lego架构采用的是compute die(compute + memory interface)和I/O die组合的形式,不同的Chiplets的数量和组合形式都可以灵活搭配,从而组合出多种不同规格的云端高性能处理器产品。
奇异摩尔作为国内首批自研I/O Die互联芯粒的公司,其2.5D通用IO Die互联芯粒集成了如D2DDDRPCIeCXL等大量存储、互联接口,最高可以支持10+Chiplets,提供更好的性能、更高的带宽、更低的延迟及功耗,构建全球领先的一流算力平台。
复兴:高性能计算和数据中心市场
“我们非常重视高性能计算和人工智能的 GPU 发展。实际上,这可能是我们开启的一个非常重要的弧线,我们一直都在研究 GPU,这是下一个重大机遇。AMD的chiplet 策略可以构建一个高度模块化的系统,可称之为集成的 CPU 和 GPU,或者说它更像是实现了人们需要的令人难以置信的 GPU 功能。”Lisa Su在接受外媒访谈时表示。
正如Lisa描述的一样,AMD这几年聚焦于HPC和数据中心并交出了斐然的成绩单。2020年, AMD官宣推出Instinct MI 100 加速卡全面进军高性能计算领域。在接下来的几年中,AMD不断升级其AI加速卡的性能。
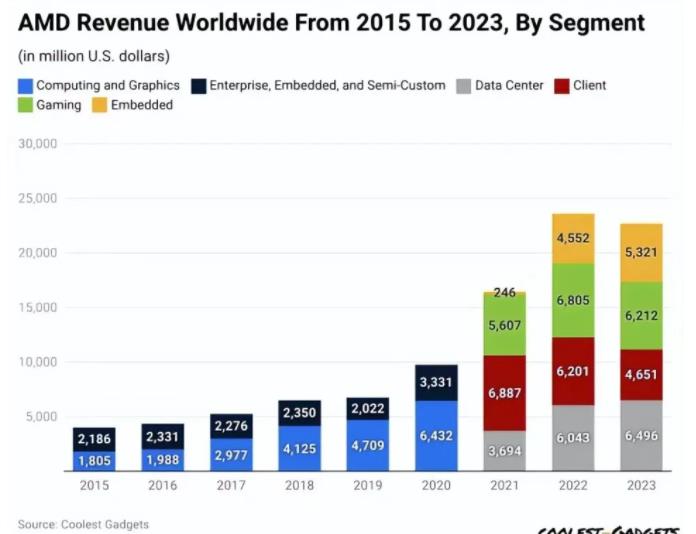
图:2023年Datacetner已经成为AMD全球收入来源最大的板块
2023年,AMD又推出了高性能GPU加速卡即Instinct MI300. Lisa 坦言AMD将AI视为第一战略重点,AI存在大量的市场机会,而最大机遇来自数据中心。MI300系列已成为AMD历史上收入增长最快的产品。Instinct MI300 是 AMD 建立未来数据中心/ HPC级APU 的重要布局,结合了 AMD 的 CPU 和 GPU 技术的优点。

值得注意的是,AMD从Zen3 架构开始就实现了3D fabric封装工艺,而I/O die作为系统基础设施的一部分,通过AMD Infinity Fabric技术与其他芯片进行互连,发挥着关键作用。在某些配置中,例如顶配版本,可能会包含4个I/O die,它们基于6nm工艺制造,并且可能包含I/O控制器、IP块以及可能的缓存。

3D Base die(可理解为基于3D封装的I/O Die)较2.5D IO die面积更大,除了IO die中的互联模块,还可以把原本集成在SoC中的Power、SRAM、I/O等非数字功能模块拆分并拼搭进去,从而构成一个高度集成并节能的多核异构计算架构,同时实现上层的逻辑芯片面积最大化和芯片单位面积的最小化。在互联方面,3D Base die支持水平方向和垂直方向的异构芯片互连。垂直方向,通过TSV、microbump等3D互连技术与顶层逻辑芯粒、substrate垂直通信,从而以最小限度实现die与die之间的互连、片外连接,显著提高芯粒集成密度。
“
Kiwi Base Die 是奇异摩尔基于Chiplet及3D IC架构所自研的基础互联芯粒。Kiwi Base Die 以高性能片上网络Kiwi Fabric 为互联核心,整合了PCle、HBM等高速互联接口,并搭配大容量的片上近存,可实现高效的片内数据传输调度与存储。客户可将其他功能单元垂直堆叠在Kiwi Base Die之上,通过 3D Die2Die 接口实现芯粒间的高速互联。
突破解耦:开源的芯世界
AMD Lisa Su在采访中表明“ 如果你看看今天的半导体行业,你会发现我们和竞争对手既有竞争的地方,也有合作的地方。行业没有一种万能的解决方案,因此模块化和开放性将允许生态系统在他们想要创新的地方进行创新。所以,比如英特尔,我们确实在某些领域竞争,但我们也在某些领域合作。英特尔是 UALink 联盟的一部分,他们也是超级以太网联盟UEC的一部分。”
AMD作为领先的国际芯片公司,倡导行业的开放开源,通过联合生态伙伴建立国际互联标准。
“目前国内的Chiplet生态处于‘半开放生态’;一是大量产品开始采用Chiplet技术,二是行业中诞生了一些专门从事Chiplet的企业,无论是提供特定芯粒,还是将已有芯片产品中的某些功能模块(芯粒)单独分离出来,以独立的Chiplet形式提供给其他企业使用。奇异摩尔就在此列。”奇异摩尔联合创始人兼产品和解决方案副总裁祝俊东此前在接受第一财经采访时提及。
未来科技还会出现很多有梦想有坚持的企业如奇异摩尔,依托Chiplet架构,不断探索下一代高性能计算及AI网络的互联芯粒技术。
写在最后
摩尔在其 1965 年关于芯片、晶体管以及芯片设计未来的开创性论文中写道,他最终能够预见到芯片制造商将芯片分解成更小的部分,以使它们更容易制造。这也是半导体鼻祖对于未来芯片架构的一个神奇的预测,也将预示行业对Chiplet技术赋予厚望,从而创造一个更简单、更开源的芯世界。
全部0条评论

快来发表一下你的评论吧 !

