

人工智能
我们可以对神经网络架构进行优化,使之适配微控制器的内存和计算限制范围,并且不会影响精度。我们将在本文中解释和探讨深度可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别的潜力。
关键词识别 (KWS) 对于在智能设备上实现基于语音的用户交互十分关键,需要实时响应和高精度,才能确保良好的用户体验。最近,神经网络已经成为 KWS 架构的热门选择,因为与传统的语音处理算法相比,神经网络的精度更胜一筹。
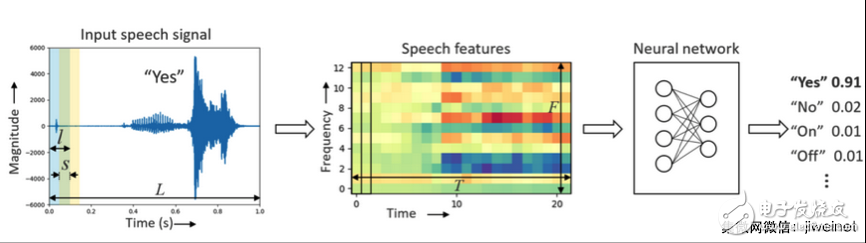
关键词识别神经网络管道
由于要保持“永远在线”,KWS 应用的功耗预算受到很大限制。虽然 KWS 应用也可在专用 DSP 或高性能 CPU 上运行,但更适合在 Arm Cortex-M 微控制器上运行,有助于最大限度地降低成本,Arm Cortex-M 微控制器经常在物联网边缘用于处理其他任务。
但是,要在基于 Cortex-M 的微控制器上部署基于神经网络的 KWS,我们面临着以下挑战:
1. 有限的内存空间
典型的 Cortex-M 系统最多提供几百 KB 的可用内存。这意味着,整个神经网络模型,包括输入/输出、权重和激活,都必须在这个很小的内存范围内运行。
2. 有限的计算资源
由于 KWS 要保持永远在线,这种实时性要求限制了每次神经网络推理的总运算数量。
以下是适用于 KWS 推理的典型神经网络架构:
• 深度神经网络 (DNN)
DNN 是标准的前馈神经网络,由全连接层和非线性激活层堆叠而成。
• 卷积神经网络 (CNN)
基于 DNN 的 KWS 的一大主要缺陷是无法为语音功能中的局域关联性、时域关联性、频域关联性建模。CNN 则可将输入时域和频域特征当作图像处理,并且在上面执行 2D 卷积运算,从而发现这种关联性。
• 循环神经网络 (RNN)
RNN 在很多序列建模任务中都展现出了出色的性能,特别是在语音识别、语言建模和翻译中。RNN 不仅能够发现输入信号之间的时域关系,还能使用“门控”机制来捕捉长时依赖关系。
• 卷积循环神经网络 (CRNN)
卷积循环神经网络是 CNN 和 RNN 的混合,可发现局部时间/空间关联性。CRNN 模型从卷积层开始,然后是 RNN,对信号进行编码,接下来是密集全连接层。
• 深度可分离卷积神经网络 (DS-CNN)
最近,深度可分离卷积神经网络被推荐为标准 3D 卷积运算的高效替代方案,并已用于实现计算机视觉的紧凑网络架构。
DS-CNN 首先使用独立的 2D 滤波,对输入特征图中的每个通道进行卷积计算,然后使用点态卷积(即 1x1),合并纵深维度中的输出。通过将标准 3D 卷积分解为 2D和后续的 1D,参数和运算的数量得以减少,从而使得更深和更宽的架构成为可能,甚至在资源受限的微控制器器件中也能运行。
在 Cortex-M 处理器上运行关键词识别时,内存占用和执行时间是两个最重要因素,在设计和优化用于该用途的神经网络时,应该考虑到这两大因素。以下所示的神经网络的三组限制分别针对小型、中型和大型 Cortex-M 系统,基于典型的 Cortex-M 系统配置。

KWS 模型的神经网络类别 (NN) 类别,假定每秒 10 次推理和 8 位权重/激活
要调节模型,使之不超出微控制器的内存和计算限制范围,必须执行超参数搜索。下表显示了神经网络架构及必须优化的相应超参数。

神经网络超参数搜索空间
首先执行特征提取和神经网络模型超参数的穷举搜索,然后执行手动选择以缩小搜索空间,这两者反复执行。下图总结了适用于每种神经网络架构的最佳性能模型及相应的内存要求和运算。DS-CNN 架构提供最高的精度,而且需要的内存和计算资源也低得多。
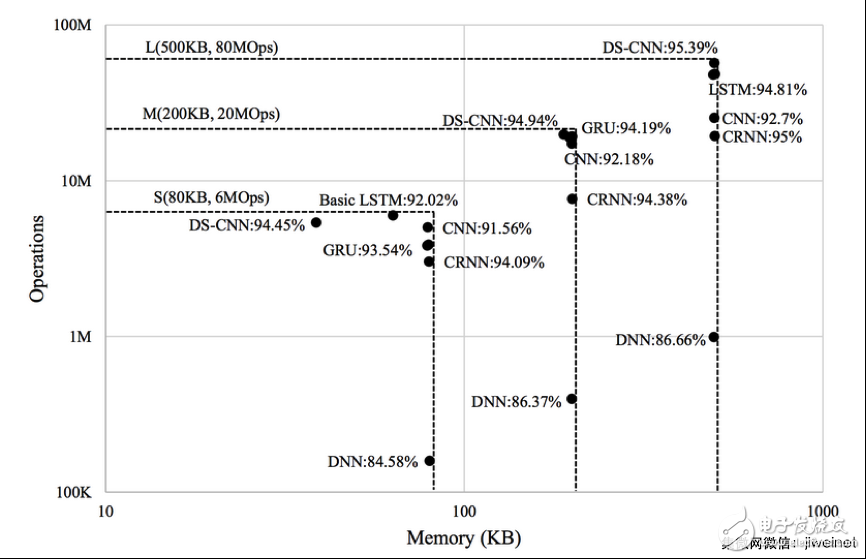
最佳神经网络模型中内存与运算/推理的关系
KWS 应用部署在基于 Cortex-M7 的 STM32F746G-DISCO 开发板上(如下图所示),使用包含 8 位权重和 8 位激活的 DNN 模型,KWS 在运行时每秒执行 10 次推理。每次推理(包括内存复制、MFCC 特征提取、DNN 执行)花费大约 12 毫秒。为了节省功耗,可让微控制器在余下时间处于等待中断 (WFI) 模式。整个 KWS 应用占用大约 70 KB 内存,包括大约 66 KB 用于权重、大约 1 KB 用于激活、大约 2 KB 用于音频 I/O 和 MFCC 特征。
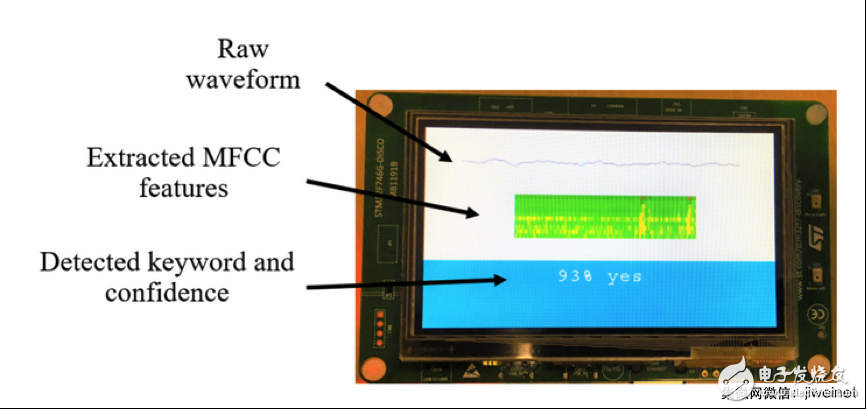
Cortex-M7 开发板上的 KWS 部署
总而言之,Arm Cortex-M 处理器可以在关键词识别应用中达到很高的精度,同时通过调整网络架构来限制内存和计算需求。DS-CNN 架构提供最高的精度,而且需要的内存和计算资源也低得多。
代码、模型定义和预训练模型可从 github.com/ARM-software 获取。
我们全新的机器学习开发人员网站提供一站式资源库、详细产品信息和教程,帮助应对网络边缘的机器学习所面临的挑战。
全部0条评论

快来发表一下你的评论吧 !

