

 嵌入式单片机MCU开发
专栏
嵌入式单片机MCU开发
专栏

 Monika观察
专栏
Monika观察
专栏



 Simon观察
专栏
Simon观察
专栏

 瑞萨电子
专栏
瑞萨电子
专栏
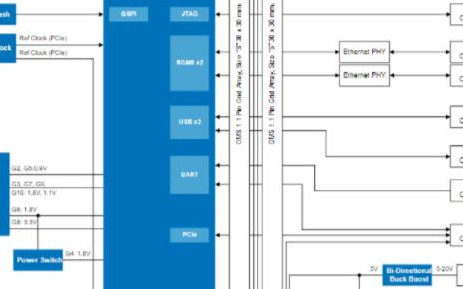
 电子发烧友网官方
电子发烧友网官方



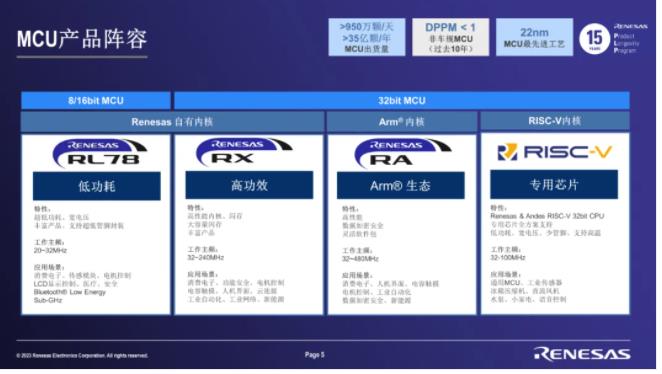
 Felix分析
专栏
Felix分析
专栏

 电子发烧友网官方
电子发烧友网官方

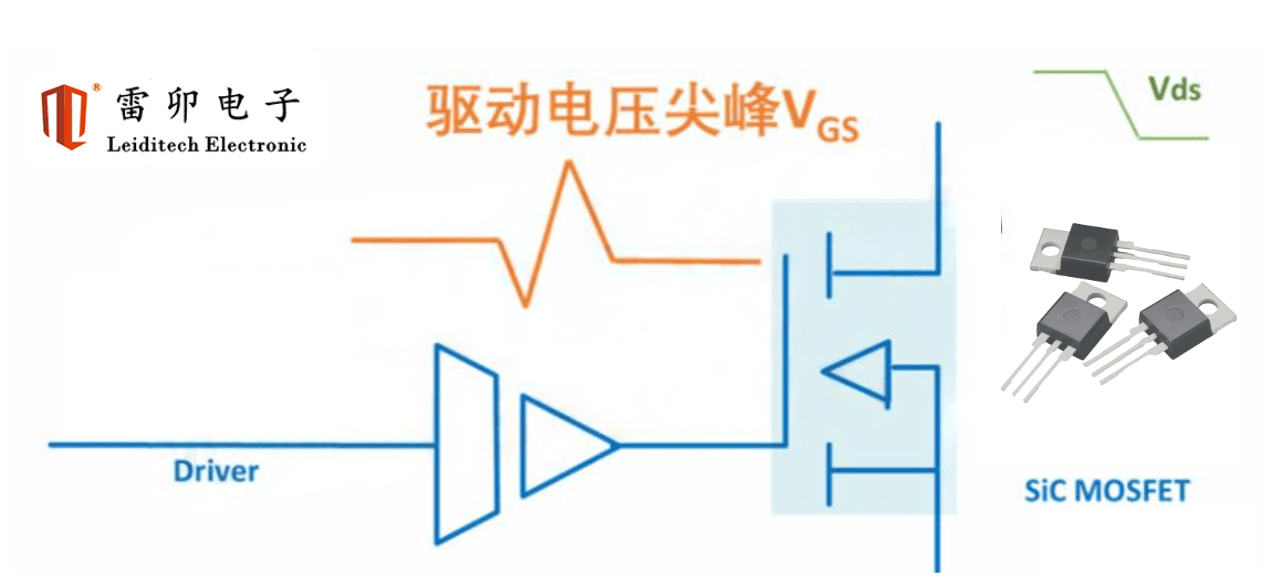


 硬核拆解
硬核拆解
 Simon观察
专栏
Simon观察
专栏


 Hobby观察
专栏
Hobby观察
专栏


 章鹰观察
专栏
章鹰观察
专栏


 下载APP
下载APP
 搜索内容
搜索内容

 业绩前景乐观 但思科仍计划裁员6300人
业绩前景乐观 但思科仍计划裁员6300人 

 10058
10058 




