

电子说
【导读】软注意力机制已在计算机视觉领域取得了广泛的应用和成功。但是我们发现硬注意力机制在计算机视觉任务中的研究还相对空白。而硬注意力机制能够从输入信息中选择重要的特征,因此它被视为是一种比软注意力机制更高效的方法。本次,将为大家介绍一种通过引入硬注意力机制来引导学习视觉回答任务的研究。此外结合 L2 正则化筛选特征向量,可以高效地促进筛选的过程并取得更好的整体表现,而无需专门的学习过程。
摘要
生物感知中的注意机制主要是用于为复杂处理过程选择感知信息子集,以对所有感官输入执行禁止操作。软注意力机制 (soft attention mechanism) 通过选择性地忽略部分信息来对其余信息进行重加权聚合计算,已在计算机视觉领域取得了广泛的应用和成功。然而,我们对于硬注意力机制 (hard attention mechanism) 的探索却相对较少,在这里,我们引入一种新的硬注意力方法,它能够在最近发布的一些视觉问答数据库中取得有竞争力的表现,甚至在一些数据集中的性能超过了软注意力机制。虽然硬注意力机制通常被认为是一种不可微分的方法,我们发现特征量级与语义相关性是相关的,并能为我们提供有用的信号来筛选注意力机制选择标准。由于硬注意力机制能够从输入信息中选择重要的特征,因此它被视为是一种比软注意力机制更高效的方法,特别地对于最近研究中使用非局部逐对操作 (non-local pairwise) 而言,其计算和内存成本的消耗是巨大的。
简介
视觉注意力有助于促进人类在复杂视觉推理多方面的能力。例如,对于需要在人群中识别出狗的任务,视觉系统能够自适应地分配更多的计算处理资源,对狗及其潜在的目标或场景进行视觉信息处理。当观察者正观察场景中的其他目标,而未发觉到一些引人注目的实体时,这种感知效果将变得非常显著。尽管注意力机制并不是计算机视觉领域中的一项变革性的技术,但由于许多计算机视觉任务,如检测,分割和分类,并没有涉及复杂的视觉推理过程,因此这种注意力机制对计算机视觉任务而言还是有帮助的。
视觉问答任务是一项需要复杂推理过程的视觉任务,在近些年得到广泛的关注并取得了长足的进步。成功的视觉问答框架必须要能够处理多个对象及其之间复杂的关系,同时还要能够集成丰富的目标背景知识。我们意识到计算机视觉中的软注意力机制主要是通过加权聚合部分重要信息来提高视觉处理的准确性,但对于计算机视觉中的硬注意力机制的研究相对空白。
在这里,我们探索一种简单的硬注意力机制,来引导卷积神经网络的特征表征:特征学习通常需要为硬注意力的选择提供一种简单的访问信号。特别地,用 L2 正则化筛选这些特征向量已被验证是一种有助于硬注意力机制的方法,它能够高效地促进筛选的过程并取得更好的整体表现,而无需专门的学习过程。下图1展示了这种方法的结果。注意力信号直接源自于标准的监督任务损失函数,而无需任何明确的监督信号来激活正则化,也无需其他潜在的措施。
图1 基于给定的自然图像和文本问题输入,我们的视觉问答架构得到的输出结果图。这里,我们使用了一种硬注意机制,只对那些重要的视觉特征进行选择并处理。基于我们模型结构,正则化后视觉特征的相关性以及那些具有高度相关性并包含重要语义内容的特征向量的前提,生成我们的注意力图像。
此外,通过对特征向量的 L2 正则化处理来选择重要性特征,我们的视觉问答框架进一步采用硬注意力机制进行增强。我们将最初的版本成为硬注意力网络 HAN (Hard Attention Network),用于通过顶层正则化项来选择固定数量的特征向量。第二个版本我们称之为自适应的硬注意力网络 AdaHAN (Hard Hard Attention Network),这是基于输入来决定特征向量的可变数量的一种网络结构。我们在大量的数据集上评估我们的方法,实验结果表明我们的算法能够在多个视觉问答数据及上实现与软注意力机制相当的性能。此外,我们的方法还能产生可解释的硬注意力掩模,其中所选的图像特征区域通常包含一些相应的重要语义信息,如一些连贯的对象。相比于非局部成对模型,我们的方法也能取得相当出色的表现。
方法
下图2展示了我们提出的用于学习从图像和问题映射到答案的模型结构。我们用卷积神经网络 (CNN) 对图像进行编码(在这里采用的是预训练的 ResNet-101 模型,或是从头开始训练小型的 CNN 模型),并用 LSTM 将问题编码为一个固定长度的矢量表征。通过将答案复制到 CNN 模型中每个空间位置并将其与视觉特征相连接,我们计算得到组合表征。经过几层组合处理后,我们在空间位置上引入注意力机制,这与先前研究中引入软注意力机制的过程是一致的。最后,我们将特征聚合,并使用池化和 (sum-pooling) 或关系模块 (relational modules),通过计算答案类别的标准逻辑回归损失来端到端地训练整个网络。
图2 我们在模型中引入硬注意力机制来代替软注意力机制,并遵循标准视觉问答框架的其他结构。图像和问题都被编码成各自的矢量表征。随后,空间视觉特征的编码被进一步表示,而问题嵌入相应地通过传播和连接 (或添加) 以形成多模式输入表征。我们的注意力机制能够有选择性地选择用于下一次聚合和处理多模式向量的应答模块。
▌1. 硬注意力机制
我们引入了一种新的硬注意力机制,它在空间位置上产生二进制掩码,并确定用于下一步处理的特征选择。我们将我们的方法称为硬注意力网络 (HAN),其核心在于对每个空间位置使用 L2 正则化激活以生成该位置相关性。L2 范数和相关性之间的关系是 CNN 训练特征的一种新属性,这不需要额外的约束或目标。我们的结构也只是对这种现象进行引导而没有明确地训练该网络。
因此,与软注意力机制相比,我们的方法不需要额外的参数学习。HAN 只需要一个额外的、可解释的超参数:即输入单元所使用的稀疏,也是用于权衡训练速度和准确性的参数。
▌2.特征聚合
池化和在引入注意力机制后,减少特征矢量的一种简单方法是将其进行池化和操作以生成长度固定的矢量。在注意力权重向量为 w 的软注意力条件下,我们很容易计算得到向量的池化和。在硬注意力条件下,基于选择的特征,我们也可以由此类比地计算。
非局部逐对操作 为进一步改善池化和的性能,我们探索一种与通过非局部成对计算来演绎推理相类似的方法。其数学描述如下:
在这里,softmax 函数作用于所有的 i, j 位置。我们的方法能够成对地计算非局部嵌入之间的关系,独立于空间或时间的近似度。硬注意力机制能够帮助我们减少所要考虑的设置,因此我们的目标在于测试通过硬注意力选择的特征是否能与此操作相兼容。
实验
为了展示硬注意力机制对视觉问答任务的重要性,我们首先在 VQA-CP v2 数据集上,将 HAN 与现有的软注意力网络 SAN 进行比较分析,并通过卷积映射直接控制空间单元出现的数量来探索不同程度的硬注意力的影响。随后,我们评估 AdaHAN 模型并研究网络深度和预训练策略的影响,这是一种能够自适应地选择单元出现数量的一种模型。最后,我们展示了定性的实验结果,并提供了在 CLEVR 数据集上的结果,以表明我们方法的通用性。
▌1.实验细节
我们的模型都使用相同的 LSTM 模型用于问题嵌入,其大小为512,并采用在 ImageNet 数据集上预训练的 ResNet-101 模型的最后一个卷积层 (能够产生10×10空间表征,每个具有2048个维度),用于图像嵌入。此外,我们还使用3层大小分别为1024、2048、1000的 MLP 结构,作为一个分类模型。我们使用 ADAM 进行优化,采用分布式设置,以128每批次大小来计算梯度值,并根据经验在Visual QA数据集上选择默认的超参数。
▌2.数据集
VQA-CP v2 数据集的结果:VQA-CP v2 数据集包含 121K (98K) 张图像数据,438K (220K) 条问题数据以及 4.4M (2.2M) 答案数据。该数据集提供了标准的训练测试过程,并将问题分解为不同的类型:如答案为肯定/否定类型,答案是数字类型,以及其他类型等,这有助于我们用每种问题类型准确性来评估网络架构的性能。
CLEVR:CLEVR 是一个合成数据库,由 100K 张 3D 渲染图像组成,如球体、圆柱体等。虽然视觉任务相对简单,但解决这个数据集也需要推理目标间的复杂关系。
▌3.结果分析
硬注意力机制的影响
我们考虑最基础的硬注意力结构:采用硬注意力机制,并对每个出现单元进行池化和操作,最后连接一个小型的 MLP 结构。下表1展示了我们的实验结果。可以看到,引入硬注意力机制不仅不会丢失特征的重要信息,还能在较少出现单元的情况下,取得相当的性能结果,这表明了这种机制是图像的重要部分。此外,在表1下面我们还与软注意力机制进行了对比,可以发现软注意力机制的表现并不优于我们的方法。
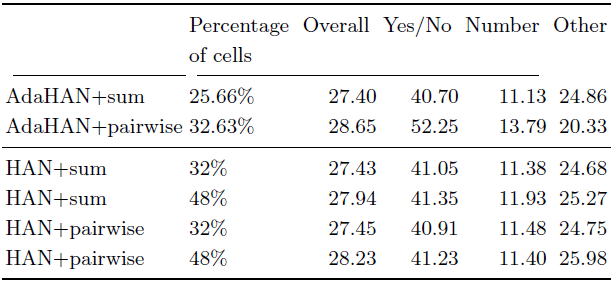
表1 不同出现单元数量和聚合操作的性能比较。我们考虑简单的和操作和非局部成对计算作为特征聚合的工具。
自适应硬注意力机制的结果
下表2展示了自适应硬注意力机制的实验结果。我们可以看到,自适应机制使用非常少的单元:进行池化和计算时,只使用100个单元中的25.66个,而进行非局部成对聚合时,则只有32.63个单元被使用。这表明即便非常简单的自适应方法,也能给图像和问题的解决可以带来计算和性能方面的提升,这也说明更复杂的方法将是未来工作的重要方向。
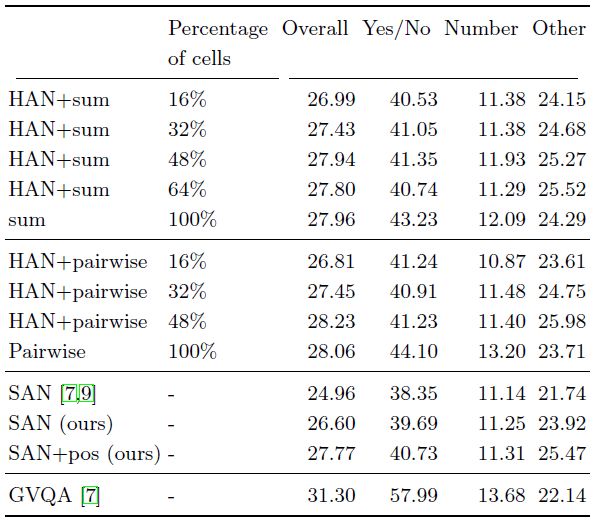
表2 不同自适应硬注意力技术、单元出现的平均数量和聚合操作的性能对比。我们考虑一种简单的和操作和非局部成对聚合操作。
此外,下表3展示了移除两层结构后自适应硬注意力机制的性能表现。可以看到,移除这些层后,模型的表现下降了约1%,这表明了决定单元出现与否需要不同的信息,这不同于 ResNet 模型的分类微调设计,同时也说明了深度对于自适应机制的影响。
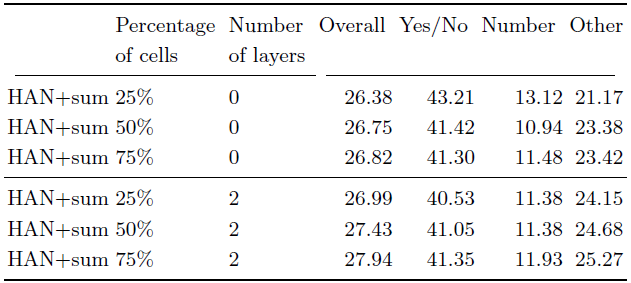
表3 在 VQA-CP v2 数据集上不同单元出现数量的性能比较。其中第二列表示输入单元出现的百分比,而第三列代表 MLP 结构的层数。
定性结果及 CLEVR 数据集结果
下图3、图4展示了我们方法的定性实验结果。图3展示了采用不同硬注意力机制(HAN、AdaHAN)、不同聚合操作 (和操作、逐对操作) 的实验结果。而图4展示了采用最佳的模型设置:自适应硬注意力机制加上非局部逐对聚合操作 (AdaHAN+pairwise),在 VQA-CP 数据集上的实验结果。
图3 不同硬注意力机制和不同聚合方法变体的定性结果
图4 AdaHAN+pairwise 的定性结果
此外,我们还进一步在 CLEVR 数据集上验证我们方法的通用性,其他的设置与 VQA-CP 数据集上相类似。下图5展示了两种方法的实验结果。
图5 在 CLEVR 数据集上相同超参数设置,不同方法的验证精度结果。(a) HAN+RN (0.25的输入单元) 和 标准的 RN 结构 (全输入单元),训练12个小时来测量方法的有效性。(b) 我们的硬注意力方法。
结论
我们已经引入了一种新的硬注意力方法用于计算机视觉任务,它能够选择用于下一步处理的特征向量子集。我们探索了两种模型:一个选择具有预定义向量数量的 HAN 模型,另一个自适应地选择子集大小作为输入的 AdaHAN。通过特征向量数量与相关信息的相关性,我们的注意力机制能够解决文献中现有方法存在的梯度问题。经过大量的实验评估,结果表明了在具有挑战性的 Visual QA 数据集上,我们的 HAN 和 AdaHAN 模型能够取得有竞争力的性能表现,并在某些时候取得相当甚至超过软注意力机制的表现,同时还能提供额外的计算效率优势。最后,我们还提供了可解释性表示,即对所选特征的空间位置中相应贡献最大、最显著的部分进行了可视化。
全部0条评论

快来发表一下你的评论吧 !

