



分享资料个
本论文介绍了双门限语音端点检测理论,研究了语音特征参数地提取过程,特征参数包括:线性预测系数(LPC)、线性预测倒谱系数(LPCC) 和Mel频率倒频系数(MFCC) 。并研究了3种不同的语音识别算法: DTW算法、VQ算法和HMM算法。并且在MATLAB环境中提取了孤立字语音(十个数字0~9的汉语发音)的LPCC、MFCC特征参数,用它们配合上述3种语音识别算法实现了对这些孤立字语音的识别。
语音识别研究开始于二十世纪50年代,Bell 实验室实现了第一个可以识别10个英文数字的语音识别系统(Audry)。
但是真正取得实质性进展是在60年代末,70 年代初,当时提出了动态时间规划(DP) 和线性预测分析技术(LP), 后者很好地解决了语音的建模问题,到了70年代初,动态时间规整(DTW) 解决语音特征长度不一致的问题。这对特定人孤立词的语音识别特别有效。70年代还提出了矢量量化VQ和隐马尔可夫模型HAOM的语音识别算法。
80年代,这时研究的重点转到了对连续语音的识别,提出了多级的动态时间规划识别算法等,此时设计方法算法从模板匹配到统计模型转变。特别是隐马尔可夫模型HMM语音识别算法的成熟和推广,。
90年代人们开始研究自然语音的识别,逐渐发展到口语对话和人机语音交互的方面。人工神经网络技术也开始用于语音识别,成为语音识别的--条新途径。
我国在80年代后期研究了人机语音对话项目,这个时候,国内的大学和研究所相继研究了语音识别。
国外许多公司为语音识别投入大量资金,推动语音识别的研究。
经过了半个世纪地研究发展,目前语音识别技术已经发展到了接近实用的阶段。在实验环境下,识别率很高,达到90%以上,在这样的基础上,语音识别走向了商品化。虽然很多公司开发除了语音识别系统,但是它还主要受到计算的性能和价格的制约,还有很多方面需要改进。
1.提高可靠性。
语音识别技术的识别率特别受到语音环境的影响,在公共场合,噪音比较大,虽然人耳可以很轻松的屏蔽掉无用信息,或不想要的信息。但是计算机不能屏蔽掉,它会对语音识别率造成严重的干扰,所以必须要采取滤出噪声等措施,提高可靠性。
2.增加词汇量。
语音识别系统应该有很大的词汇量,让语音识别系统的功能更强大,作用更广人机交互更加智能化,使人们更加方便使用机器。
3.应用拓展。
可以使用语音识别系统开发- -些应用,使人们生活水平更高,更加智能化,享受舒适温馨的生活。
4.降低成本减小体积。
任何技术商品化,都必须要降低成本,使普遍人们能够使用的起,小体积的识别系统更符合人们的需要,就像计算机一样,从开始的研发的大型计算机,到民用的个人计算机,体积缩小了很多。
21世纪是信息和网络的时代,Internet、 智能手机、计算机、物联网、移动电话网将会把全球的人与人之间、人与物之间、和物与物之间都相互连接起来。而自然口语对话、智能家居、信息索取、电子商务、语音翻译、数字图书馆等领域,语音识别技术将发挥巨大的作用。
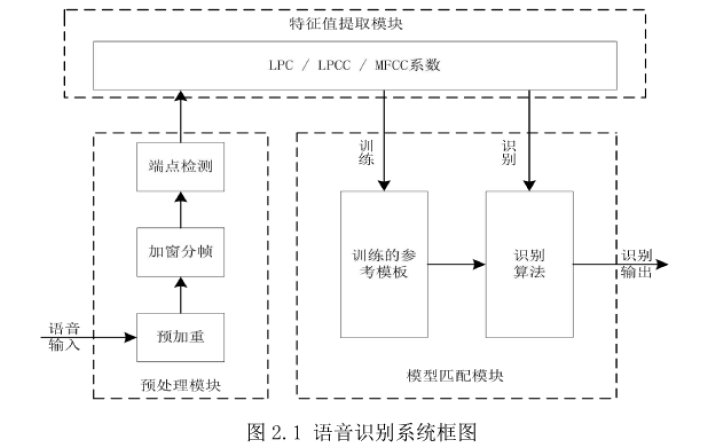
本论文描述了基本的语音识别基本原理,介绍了语音识别的-般过程。在第二章介绍语音识别的算法所需要的参数提取的过程,包括语音信号预加重、分帧、端点检测, LPCC和MFCC意义和它的提取过程。第三章介绍了动态规划DTW算法、矢量量化算法和隐马尔可夫模型HMM算法语音识别,第四章得出了语音识别的实验结果。第五章做出总结。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉




全部0条评论

快来发表一下你的评论吧 !
