



分享资料个
对于 5G 蜂窝和机器学习 DNN/CNN这 样的计算密集型应用,赛灵思的新型向量处理器 AI 引擎由一系列 VLIW SIMD高性能处理器构成,可提供高达 8 倍的芯片计算密度,功耗却比传统可编程逻辑解决方案低 50%。
本白皮书探讨了将赛灵思新 AI 引擎用于计算密集型应用(如 5G 蜂窝和机器学习 DNN/CNN)的架构、应用和优势。
与前几代相比,5G 的计算密度要高 5 到 10倍;AI 引擎已针对 DSP 进行了优化,可满足吞吐量和计算要求,从而提供无线连接所需的高带宽和加速速度。
许多产品中机器学习的采用(通常采用 DNN/CNN 网络的形式)大大增加了计算密度要求。AI 引擎针对线性代数进行了优化,可提供满足这些要求的计算密度,同时与可编程逻辑中执行的类似功能相比,功耗也降低了50%。
AI 引擎使用了许多程序员所熟悉的 C/C++ 范例进行编程。AI 引擎与赛灵思的自适应与标量引擎集成,可提供高度灵活且功能强大的整体解决方案。
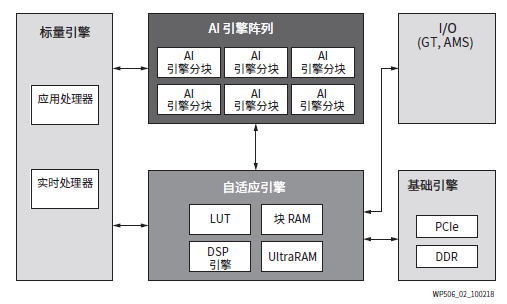
赛灵思产品在计算密集型应用方面坐拥数十年的实施历史,该领域的开拓始于 90 年代初的高性能计算 (HPC) 和数字信号处理 (DSP)。FPGA的赛灵思 XC4000 系列 FPGA 已成为支持商用和航空航天与国防无线通信系统数字前端 (DFE) 解决方案的关键技术。这些早期实践者使用 LUT 和加法器 实现计算元素(例如乘法器),以构建 DSP 功能数、FIR 滤波器和 FFT。
2001 年为 Virtex-II 系列 FPGA 开发的第一个“DSP 片”。遵照摩尔定律,赛灵思将 LUT 数量从XC4000 FPGA 中的 400 个增加到现有器件中的 370 多万个 LUT 和超过 12,200 个 DSP 片,将可用资源增加了 9,500 多倍。随着计算资源的不断增加,赛灵思产品始终能够提供所需的计算密度和逻辑资源,紧跟新兴信号处理市场的步伐。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉



全部0条评论

快来发表一下你的评论吧 !
