

电子说
而今,深度学习大行其道。
结果来看,它是能说会画外加打游戏,但这是如何实现的?模型里的中间数据有什么意义?换句话说,模型训练中所生成的高维数据如何进行有意义的理解?
这离不开非监督学习解耦表征(Unsupervised Learning of Disentangled Representations)。
一个在好奇心驱动的探索(curiosity driven exploration)、抽象推理(abstract reasoning)、视觉概念学习(visual concept learning )等方面早已用起来的方法。
但是目前,并未有什么方案可以统一衡量非监督学习解耦表征的有效性和局限性。即,解耦表征所得出的因子是否真正独立?某些解耦表征指标是否的确代表解耦的有效程度?
为解决这一问题,Francesco Locatello等人在“Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations ”(ICML 2019)一文中,对目前最佳的一些非监督解耦表征模型做出了大规模可复现评估,并指出了一些未来发展方向,造福业界人士。
该评估经由7个不同数据集上超12000个模型得出,涵盖了对业界最佳的解耦方法以及一些评估指标的评测,不仅可复现,而且该研究的代码和10800个预训练好的模型都已开源在disentanglement_lib,研究者们也可以将自己的解耦模型在此进行统一评估,与其他解耦模型进行对比,非常棒。
啥是解耦
通俗来讲,解耦就是将一个对象分解为各自独立的因素。不同的因素控制不同的结果,一个因素只控制一个结果的改变。解耦表征,也就是找出对象特征里的可解释因子,从而对高维的数据产生有意义的理解。
非监督解耦认为,现实世界的数据是由一些可解释的独立因子不同组合产生的,可以通过非监督学习的方式找到这些独立因子。如在Shapes3D数据集中,每个图像由六个独立因子控制,分别是:物体形状、物体大小、相机角度、地板颜色、墙壁颜色,物体颜色。
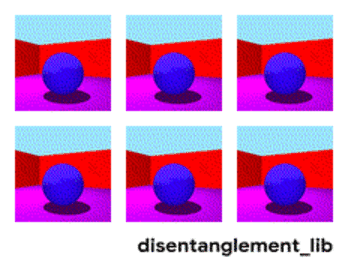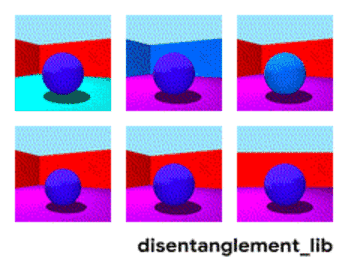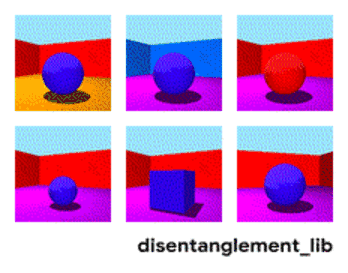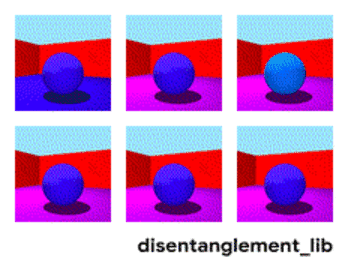
图 | Shapes3D数据集的独立真值因子可视化:地板颜色:上左;墙壁颜色:上中;物体颜色:上右;物体尺寸:下左;物体形状:下中;相机角度:下右。
解耦表征希望捕捉到这些独立因子,下图中每个3D图像数据是10维的数据,用FactorVAE解耦模型(一种变分自编码器variational autoencoders,即VAE的变种)对3D图像进行解耦,企图找出十维数据的每一维度信息,也即独立控制因子,结果有些因子被成功分离,而有些因子仍然未被捕捉。上右和上中表明,模型成功分解了地板颜色,然而,下左一和下左二两图表明物体颜色和尺寸仍未被分解开来,物体的颜色和大小都在变化,说明控制的两个因子并未独立分解。
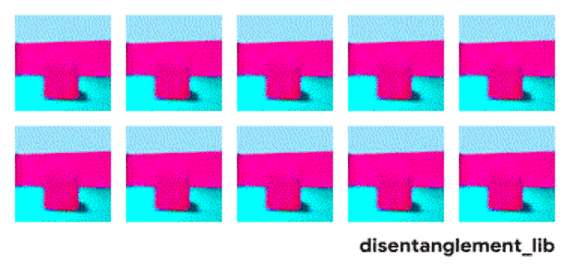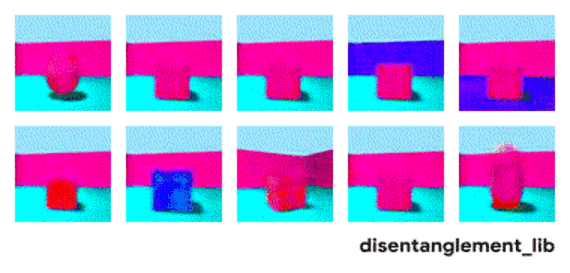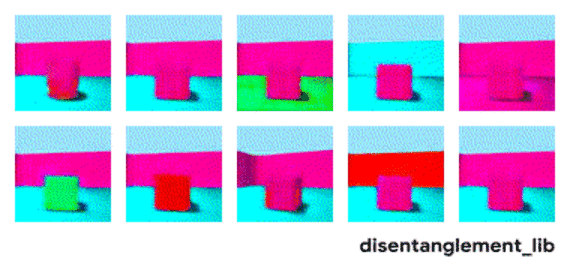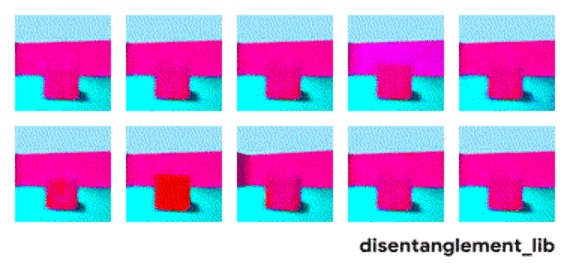
图 | 可视化用FactorVAE模型所学到的隐含维度信息。墙壁颜色、地板颜色、相机角度被成功分解(见上右一、上中、和下中);物体的形状、尺寸、颜色还未被分解出来(见上左一和下左一、下左二)
本大型可复现研究的关键结论
为了理解高维数据,目前已有大量的非监督解耦模型。这些解耦模型一般基于变分自编码器(variational autoencoders, VAE,一种非监督生成模型,通过将数据分解出独立隐含因子来进行数据的生成,也即将高维数据映射成低维数据,并且低维数据的每一维度都独立控制着该数据的某一个性质)衍变而来,同时研究者们也设计了一些度量指标来衡量解耦水平,但实际上,并没有一个大规模的可复现实验来对这些模型及指标做出统一的衡量。
为解决这一问题,Francesco Locatello等人对六个现有最佳模型(BetaVAE,AnnealedVAE,FactorVAE,DIP-VAE I / II和Beta-TCVAE, 以上皆为变分自编码器的变种)和六个解耦指标(BetaVAE评分,FactorVAE评分,MIG,SAP,Modularity和DCI Disentanglement)的实际解耦的程度做了统一的可复现衡量实验,通过7个数据集上12800个模型的训练,衡量模型和参数的实际效果,他们有了这样的发现:
1、无法证实解耦模型的确可以进行可靠的解耦。
解耦模型的结果,即所分析出的独立因子并不是每次都确定,会随着模型的改变而变化,也就是说,分析出的独立因子并不是真正的唯一控制因子。解耦表征是非监督的,如果没有一些真值标签,其实无法衡量是否成功解耦。如想对解耦进行衡量,必须提前规定好数据集和模型的归纳偏好(Inductive Bias)。即,必须有假设才能知晓结果是否吻合假设,如果什么假设都没有,那就无法衡量结论好坏。
将不同解耦模型在同一个数据集上多次训练,只是每次随机数不同,解耦指标FactorsVAE分数的分布跨度很大,即使同一个模型,仅仅随机数不同,FactorsVAE分数就会变化,并且该影响超过了正则化强度所能施加的影响。因此这种解耦表征的结果不固定,所解出的因子便难以称之为独立因子,毕竟我们设想现实世界中的对象是由确定因素以某种组合造成的。
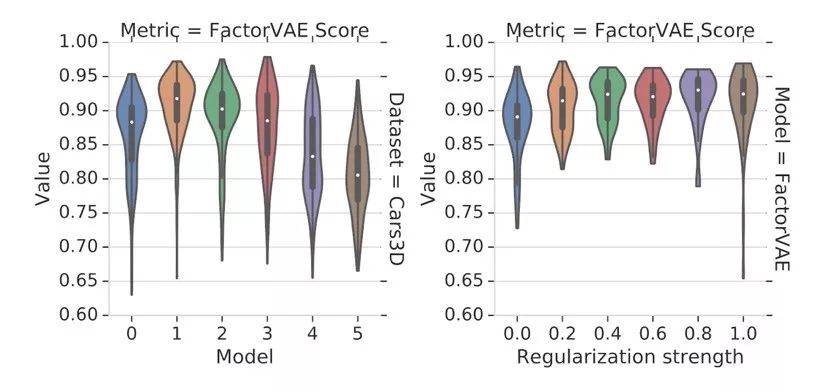
图 | 不同模型在Cars3D数据集上FactorsVAE分数的分布:左图是不同分解模型的FactorsVAE分布;右图是FactorVAE模型不同正则化强度的FactorsVAE分布。
2、解耦表征有益于下游任务(如分类任务)也是无法证实的。
FactorVAE分数和分类表现(基于Gradient Boosted Trees,GBT)并没有什么相关性,也就是FactorVAE分数高的解耦模型,利用模型解出的因子实现的分类任务表现也不一定就很好。
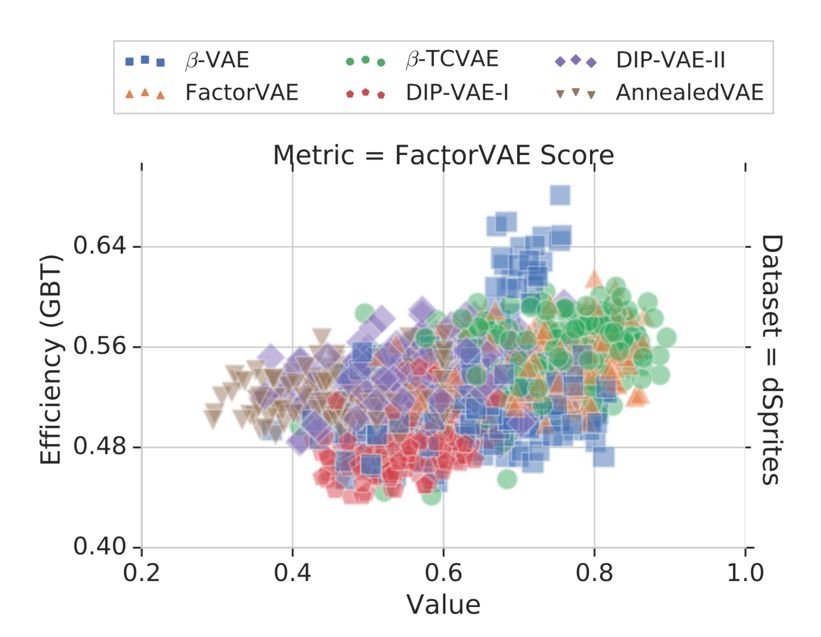
图 | 利用相应解耦模型的下游分类任务在dSprites数据集上的表现
由此,他们得出了这样一些见解:
1. 进行非监督的解耦表征需设置归纳偏好。未来工作需要明确描述强加的归纳偏好并明确是否利用了显性和隐性监督。
2. 找到好的能适用多个数据集的非监督模型归纳偏好非常关键。
3. 应证明引入解耦表征举措的具体实际益处。
4. 解耦模型效果应该在多种数据集上具有可重复性。
开源解耦表征库
该研究所用评估流程及方法、所用解耦模型(10800个,有一些模型关于Shapes3D不可用)、所采用的解耦衡量指标,以及一些帮助理解模型的可视化工具都开源在disentanglement_lib(https://github.com/google-research/disentanglement_lib)此库优点有三:
易复现。少于4个shell命令,disentanglement_lib即可重现评估所用的任何模型。另,虽所用参考模型所需算力非常之巨,但别怕,10800个预训练好的模型已奉上。
能修改。可对实验方案可以进行一些修改,验证你自己的想法。
易扩展。该库可实现公正统一的、可复现的,标准化的评估,可以轻松地将自己的新模型与参考模型对比。
全部0条评论

快来发表一下你的评论吧 !

