



分享资料个
古诗词是中华优秀传统文化上璀璨的明珠,两千年来,我国优秀诗人辈出,其诗作若满天繁星,内容丰富影响深远。随着计算机技术的不断发展,推荐系统在我们的生活中处处可见,为越来越多的用户提供了便利。然而,目前对于古诗词的个性化智能推荐系统比较匮乏,绝大多数的诗词网站也只是对于诗词内容的简单展示,而非推荐,所以进行古诗词推荐方面的研究对于促进中华优秀传统文化的传播具有重要意义。本文基于Word2vec模型,通过利用网络上爬取的古诗词数据进行训练,实现了古诗词的个性化推荐。
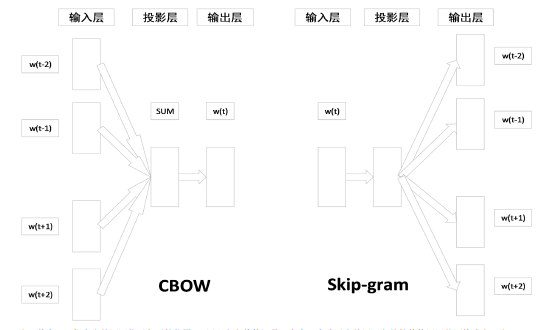
本文首先利用开源爬虫框架Requests 从互联网上爬取需要的古诗词数据,然后将爬取到的每一首古诗词的译文和赏析利用Python 中的jieba 分词库进行分词、去噪,生成古诗词语料库,进而利用该语料库训练Word2vec 模型,并通过该模型得到每一首古诗词在该语料库中的向量表示,最后使用余弦距离计算出古诗词之间的相似度,选取相似度最高的十首古诗进行推荐。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉



全部0条评论

快来发表一下你的评论吧 !
